Parce que ce modèle dédié à un locuteur est suffisamment précis, on va pouvoir l'utiliser pour représenter (transmettre) des images réelles : celles de cette même personne en train de parler devant une caméra. Par la technique d'analyse descendante proposée pour le projet Tempo Valse, on trouvera des valeurs pour les quelques paramètres (2 à 6 selon la précision voulue) du modèle de synthèse qui permettent de coder et donc d'émettre une bonne approximation de chaque image d'une sène de parole naturelle. On préservera alors du message audio-visuel original son lien image/parole, et donc le gain d'intelligibilité associé, ainsi que la ressemblance au locuteur. Ce même modèle (fixé une fois pour toutes), avec ces paramètres qui varient dans le temps sont utilisés par le terminal récepteur pour synthétiser en temps réel une image du correspondant distant, même à travers un réseau à très bas débit.

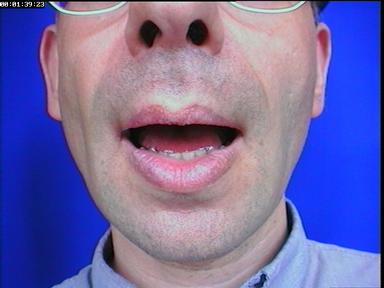
Images de clones texturés, sans dents de synthèse