Analyse et synthèse de têtes parlantes
I/ Résumé du principe
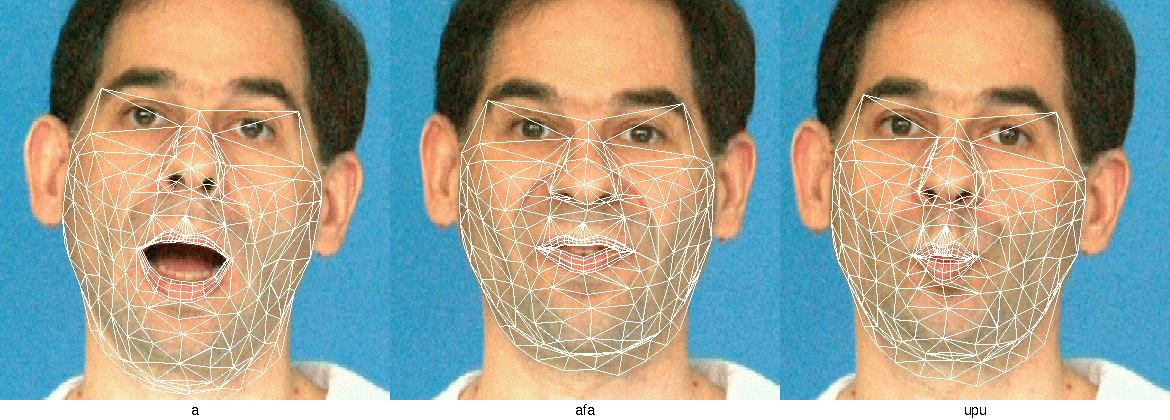
II/ Le modèle articulatoire
III/ Modèle pour la synthèse
Actuellement, une grande partie du modèle articulatoire est aussi
utilisée directement comme modèle de rendu : un maillage
relie directement les points 3D définis par le modèle linéraire.
Seule la zone des lèvres est synthétisée avec plus
de polygones, grâce au modèle générique procédural,
qui permet de raffiner leur définition jusqu'à la précision
voulue.
Dans tous les cas, c'est surtout la texture dont on va habiller ce
maillage géométrique qui rendra le modèle ressemblant
à un niveau de détail suffisant. En pratique, on a même
intérêt à utiliser plusieurs textures, pour couvrir
l'apparition de détails de parole qui ne pourraient pas être
capturées assez finement par une géométrie de taille
raisonnable : le pli qui se matérialise à la frontière
intérieure de la joue en est un bon exemple.
La synthèse d'une vue intermédiaire s'apparentera alors
à du Morphing 3D : on mélange (technique du Blending) pixel
à pixel des images déformées (principe du Warping)
selon le modèle articulatoire du locuteur.
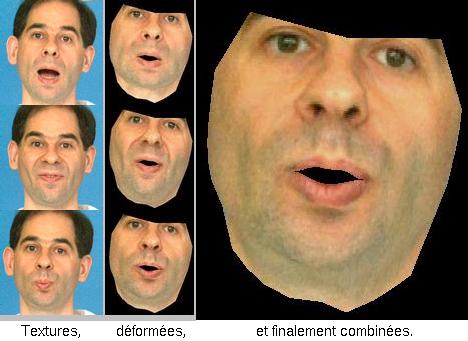
Création d'une nouvelle vue texturée par Morphing 3D multi-référence
Suite au développement du marché du jeu sur PC, ces machines
disposent actuellement de cartes graphiques peu onéreuses qui gèrent
ces primitives 3D et permettent de calculer facilement et rapidement une
image du modèle. La synthèse de modèles 3D animés
et texturés n'est donc pas un problème sur ce type de machines
cibles. On va donc s'intéresser à la partie plus problématique,
celle du choix des textures à utiliser.
1/ Synthèse avec textures multiples
Pour des raisons d'efficacité, il n'est bien sûr pas possible
d'utiliser un trop grand nombre de textures : celles-ci pourraient ne pas
tenir dans la mémoire dédiée de la carte graphique,
et il finirait par y avoir trop de passes de rendu, ce qui dégraderait
la vitesse de synthèse. De plus, le mélange de textures est
susceptible de créer un effet de flou, qu'il est plus facile de
contrôler avec un nombre limité de textures. En pratique,
3 à 5 textures semblent être un maximum raisonnable.
a/ Choix de textures visèmes
On cherche un sous-ensemble des 34 textures qui couvrent au mieux l'espace
articulatoire mesuré. Pour cela, on a besoin d'une distance : on
utilisera la distance euclidienne, directement sur
les coordonnées des points 3D des modèles. Dans le cas où
l'on cherche trois visèmes aussi différents que possible,
cela revient à maximiser :
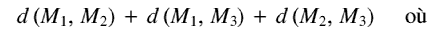
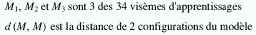
On retient les trois textures associées à ces visèmes.
Dans le cas de notre modèle, il s'agit de ceux-ci :
Les trois textures extrêmes et la configuration de modèle associée
b/ Mélange de textures de visèmes
Dans le cas de 3 textures, et pour texturer un visème cible M, on forme une texture combinée, mélangées pixel à pixel selon trois coefficients de la forme :
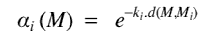
Ce paramétrage assure que chacune des textures de définition
sera utilisée de façon prépondérante lorsque
le modèle approchera la forme associée.
Pour conserver la luminosité moyenne des images, et pour que
les valeurs calculées pour chaque pixel restent affichables, il
faut que ces coefficients soient dans l'intervalle [0,1] et que leur somme
reste toujours égale à 1. On force cette dernière contrainte en normalisant leur somme.
Le choix des coeeficients k règle la suprématie d'une texture sur les autres. Pour minimiser les
problèmes de flou dans ces situations d'apprentissage, on minimise
:
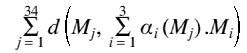
c/ Problème des angles de vue
Dans le cadre du projet Tempo Valse, l'angle de vue est naturellement fixé
au cas du vis-à-vis, puisque la restitution se fait face au casque.
Avec les images des textures d'apprentissage, de face, on est dans d'excellentes
conditions pour restituer une image de qualité.
d/ Résultats
La synthèse d'un visème réalisant un i permet de voir la différence (le gain) qui résulte des textures combinées :

Une mème configuration, sans puis avec texture combinée
On verra plus loin comment ces images pourront être comparées
à celle du corpus d'apprentissage, pour quantifier le gain.
2/ Conclusion de la synthèse
Avec un maillage animé de façon réaliste par le modèle
articulatoire et un jeu de texture propre à restituer les détails
dynamiques du visage, on est à même de créer des images
synthétiques du locuteur qui a servi de modèle. Pour dépasser
le cadre de l'image ressemblante, pour que ce clone se comporte dynamiquement
comme son modèle et qu'il véhicule le message labial de son
alter
ego, il va falloir trouver à chaque instant de la séquence
de synthèse le bon jeu de paramètres articulatoires.
IV/ Techniques d'analyse
V/ Génération et interprétation de FAPs MPEG-4