
 1.2MB .avi
1.2MB .avi 2MB .avi
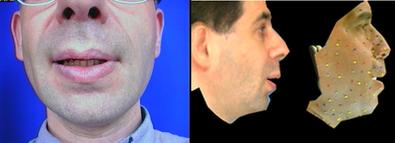
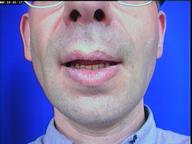
2MB .aviThe next sequences show some realistic looking reconstructions (black background) of another video message (original on blue background), either on the original locutor (left) or another one.
 1MB .avi |
 2MB .avi |
 1.2MB .avi |
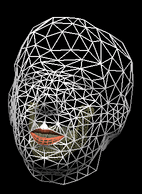
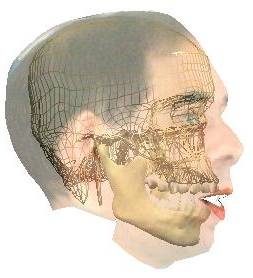
Reconstruction is 3D, as can be noticed from the previous 3D movements of the lips (reconstructed using only front view information !) or on the next sequence, where the reconstructed talking head is rotating.
 |
Full sequence (36 sec, 20MB, avi) Intro sentence (7 sec, 4MB, avi) Half resolution intro (7 sec, 2MB, avi) |
We can also construct a temporal model of his speech activity (capturing coarticulation of the visemes), and build a text to audio-visual speech synthetisor. The next video just shows a resulting sentence (in french).
 10MB .avi
10MB .avi
I was involved in the now finished Tempo Valse RNRT research project, which is a special case of audiovisual communication, involving only front-view images, a la visiophone. Very good intelligibility with very low bandwidth are concilied by transmitting only the articulatory parameters (in what we call a labiophone). That way, the synthetic videos express better quality and transmit faster than the big .avi files on this page...
Details can be browsed (in french, but with lot of pictures and some videos), about these points :
The ARTUS RNRT project (in french) is much related to the present page, adding modeling, cloning and synthesis of the face+hand speech activity for head-impaired or death people.
You may also browse
my main page about other projects and results involving talking heads.
| Page updated on 24/04/2001 | Back to F. Elisei home |