BAILLY
Gérard
Directeur de Recherche CNRS
Research
Human-Robot Interaction

Our iCub robot Nina
was born on 2013 Oct 1st. Her biological parents are at the Italian
Institute of Technology (IIT) in Genova. In collaboration with IIT, we
developped a talking face with jaw and lips articulations. We are
currently working on multimodal Human-Robot interaction, including
robot-mediated Human-Human interaction via immersive
téléoperation.
For further reading:
Studying, modelling and
tracking facial movementsFor further reading:
- Nguyen, D.-C., G. Bailly and F. Elisei (2017) An evaluation Framework to Assess and Correct the Multimodal Behavior of a Humanoid Robot in Human-Robot Interaction, Gesture in Interaction (GESPIN), Posznan, Poland: pp. 56-62.
- Nguyen, D.-C., G. Bailly and F. Elisei (2016) Conducting neuropsychological tests with a humanoid robot: design and evaluation. IEEE Int. Conf. on Cognitive Infocommunications (CogInfoCom), Wroclaw, Poland, pp. 337-342.
- Foerster F., G. Bailly and F. Elisei (2015) Impact of iris size and eyelids coupling on the estimation of the gaze direction of a robotic talking head by human viewers. Humanoids, Seoul, Korea: pp.148-153.
- Parmiggiani A., M. Randazzo, M. Maggiali, G. Metta, F. Elisei and G. Bailly (2015) "Design and Validation of a Talking Face for the iCub", International Journal of Humanoid Robotics, 1550026:1-20.
- Bailly G., F. Elisei and M. Sauze (2015). Beaming the gaze of a humanoid robot. Human-Robot Interaction (HRI) Late Breaking Reports, Portland, OR: pp.47-49.
- Boucher, J.-D., U. Pattacini, A. Lelong, G. Bailly, P. F. Dominey, F. Elisei, S. Fagel and J. Ventre-Dominey (2012) "I reach faster when I see you look: Gaze effects in human-human and human-robot face-to-face cooperation." Frontiers in neurorobotics 6(3), DOI: 10.3389/fnbot.2012.00003.
- Sauze, M., G. Bailly and F. Elisei (2014). Where are you looking at? Human perception of the gaze direction of a robotic talking head for situated interaction. Humanoids, Madrid.
In line with the work
initiated by the
late Christian Benoît and thanks to a critical mass of
researchers (my colleagues Pierre Badin and
Frédéric
Elisei, my former PhD students Mathias Odisio, Maxime Bérar,
Pierre Gacon, Oxana Govokhina, in collaboration with Pierre-Yves Coulon
and Michel Desvignes from LIS and Gaspard Breton from Orange Labs), we
have developped multiple virtual clones of human speakers for different
languages (French, English, German, Autraslian English,
Japanase, etc). Original data-driven control, shape and
appearance
models have been developped that mimick the movements of visible - and
also internal articulators - organs when speaking. The combination of
speech and facial expressions that recruits the lower face (smiling,
disgust) has also been studied. These models are used to analyse,
synthesize and track audiovisual speech.
For further reading
Face-to-face communicationFor further reading
- Bailly, G., O. Govokhina, F. Elisei and G. Breton (2009). "Lip-synching using speaker-specific articulation, shape and appearance models." Journal of Acoustics, Speech and Music Processing. Special issue on "Animating Virtual Speakers or Singers from Audio: Lip-Synching Facial Animation", ID 769494: 11 pages.
- Badin, P., Elisei F., Bailly, G., Savariaux, C., Serrurier, A. & Tarabalka, Y. (2007). "Têtes parlantes audiovisuelles virtuelles : Données et modèles articulatoires - applications." Revue de Laryngologie, 128(5), 289-295.
- Beautemps, D., P. Badin and G. Bailly (2001). Degrees of freedom in speech production: analysis of cineradio- and labio-films data for a reference subject, and articulatory-acoustic modeling. Journal of the Acoustical Society of America, 109(5): 2165-2180.
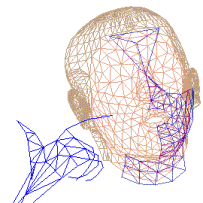
Gaze
patterns. With
Frédéric Elisei and Stephan Raidt, we have
studied mutual gaze patterns during face-to-face conversations. We have
shown that the cognitive states and respective roles of the
interlocutors in the conversation has an impact on the
distribution of fixations among the different regions of interest in
the face (left or right eye, mouth, nose ridge, etc.) as well as
blinking rate. Our aim is to develop not only talking heads but
conversational agents that are aware of the mental states of
its human interlocutor(s) and signal it by appropriate
behaviour.
For further reading: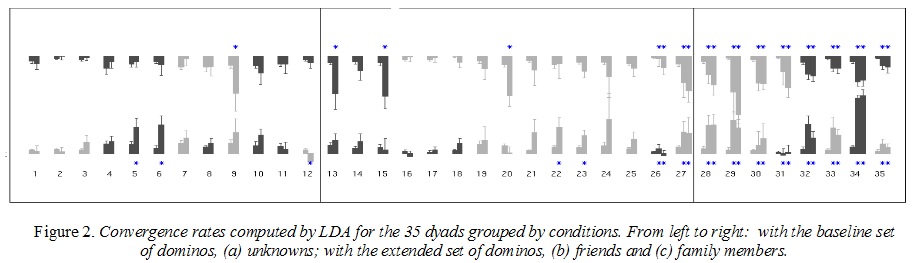
 Together with
Véronique Aubergé, we have developped a
prosodic model that directly encodes
communicative functions by superposing and overlapping
multiparametric prosodic contours. Plinio Barbosa demonstrated the
existence of rhythmic contours encoding the hierarchy of syntactic
constituents. These contours for French are not only characterized by a
final lengthening depening of the importance of the syntactic break but
by a gradual deceleration when considering the sequence of P-centers of
the part-of-speech. We also proposed to consider the pause as
an
emergent phenomenon in the process of distributing the planned rhythm
among the constituents of each syllable. Yann Morlec and Bleike Holm
worked on trainable prosodic model able to recover and generate
elementary multiparametric prosodic contours from the observation of
multiple occurences thanks to statistical modelling. The trainable SFC
(Superposition of Functional Contour) model was confronted to several
languages (French, German, Spanish, Chinese, etc.) and various
linguistic content including spoken maths.
Together with
Véronique Aubergé, we have developped a
prosodic model that directly encodes
communicative functions by superposing and overlapping
multiparametric prosodic contours. Plinio Barbosa demonstrated the
existence of rhythmic contours encoding the hierarchy of syntactic
constituents. These contours for French are not only characterized by a
final lengthening depening of the importance of the syntactic break but
by a gradual deceleration when considering the sequence of P-centers of
the part-of-speech. We also proposed to consider the pause as
an
emergent phenomenon in the process of distributing the planned rhythm
among the constituents of each syllable. Yann Morlec and Bleike Holm
worked on trainable prosodic model able to recover and generate
elementary multiparametric prosodic contours from the observation of
multiple occurences thanks to statistical modelling. The trainable SFC
(Superposition of Functional Contour) model was confronted to several
languages (French, German, Spanish, Chinese, etc.) and various
linguistic content including spoken maths.
For further reading:
Augmented speech
communication
 Together
with Denis Beautemps, Pierre Badin and Thoams Hueber, we develop speech
technologies
that can help people with temporary or permanent motor or perceptual
deficits or disabilities to communicate. These constraints may be due
to cognitive or physiological handicaps of the interlocutors
themselves, to impoverished communication channels or to adverse
environnements. These technologies aim at enhancing, enriching or
replacing the degraded communication signals with enhanced synthetic
signals thanks to the priori knowledge of the intrinsic coherence of
the multimodal signals. Potential sources of coherence comprise generic
virtual talking heads that can be adapted to the speaker
characteristics as well as linguistic constraints that can
used
in the restauration process when the language being spoken is known.
Such technologies include cued speech synthesis and recognition,
acoustic-to-articulatory inversion, voice conversion. With
Hélène Loevenbrück and in collaboration
with Tomoki
Toda from NAIST, Viet-Anh Tran has proposed an enhanced system
for
murmur-to-speech conversion with an application to silent speech
communication. With Pierre Badin and in the framework of the ARTIS
project, Atef Ben Youssef is working on data-driven statistical
audiovsiual-to-articulatory inversion for language training.
Together
with Denis Beautemps, Pierre Badin and Thoams Hueber, we develop speech
technologies
that can help people with temporary or permanent motor or perceptual
deficits or disabilities to communicate. These constraints may be due
to cognitive or physiological handicaps of the interlocutors
themselves, to impoverished communication channels or to adverse
environnements. These technologies aim at enhancing, enriching or
replacing the degraded communication signals with enhanced synthetic
signals thanks to the priori knowledge of the intrinsic coherence of
the multimodal signals. Potential sources of coherence comprise generic
virtual talking heads that can be adapted to the speaker
characteristics as well as linguistic constraints that can
used
in the restauration process when the language being spoken is known.
Such technologies include cued speech synthesis and recognition,
acoustic-to-articulatory inversion, voice conversion. With
Hélène Loevenbrück and in collaboration
with Tomoki
Toda from NAIST, Viet-Anh Tran has proposed an enhanced system
for
murmur-to-speech conversion with an application to silent speech
communication. With Pierre Badin and in the framework of the ARTIS
project, Atef Ben Youssef is working on data-driven statistical
audiovsiual-to-articulatory inversion for language training.
For further reading:
For further reading:
- Boucher J.-D., U. Pattacini, A. Lelong, G. Bailly, P. F. Dominey, F. Elisei, S. Fagel and J. Ventre-Dominey (2012) "I reach faster when I see you look: Gaze effects in human-human and human-robot face-to-face cooperation", Frontiers in neurorobotics 6(3),
- Bailly, G., S. Raidt & F. Elisei (2010) "Gaze, conversational agents and face-to-face communication", Speech Communication - special issue on Speech and Face-to-Face Communication, 52(3): 598–612.
- Bailly, G., F. Elisei and S. Raidt (2008). "Boucles de perception-action et interaction face-à-face." Revue Française de Linguistique Appliquée XIII(2): 121-131.
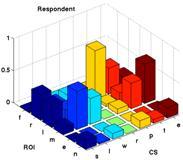
With
Amélie Lelong, we have
studied mutuial adaptation speech patterns during speech games named
"speech dominos". This very simple game consists in chaining words that
begin with the same syllabe as the last previously uttered word. We
have shown that the degree of phonetic convergence - estimated with
reference to words spelled alone - largely depend on previous exposure
to your interlocutor (friends converge more than unknowns) and social
relations (in particular dominance).
For further reading:
Modelling prosodyFor further reading:
- Bailly G. and A. Martin (2014). Assessing objective characterizations of phonetic convergence. Interspeech, Singapour: pp.2011-2015.
- Lelong, A. & G. Bailly (2012). Original objective and subjective characterization of phonetic convergence. International Symposium on Imitation and Convergence in Speech. Aix-en-Provence, France.
- Lelong, A. and G. Bailly (2011). Study of the phenomenon of phonetic convergence thanks to speech dominoes Analysis of Verbal and Nonverbal Communication and Enactment: The Processing Issue. A. Esposito, A. Vinciarelli, K. Vicsi, C. Pelachaud and A. Nijholt. Berlin, Springer Verlag: 280-293.
- Bailly G. & A. Lelong (2010). Speech dominoes and phonetic convergence. Interspeech. Tokyo, p.1153-1156.
Together with
Véronique Aubergé, we have developped a
prosodic model that directly encodes
communicative functions by superposing and overlapping
multiparametric prosodic contours. Plinio Barbosa demonstrated the
existence of rhythmic contours encoding the hierarchy of syntactic
constituents. These contours for French are not only characterized by a
final lengthening depening of the importance of the syntactic break but
by a gradual deceleration when considering the sequence of P-centers of
the part-of-speech. We also proposed to consider the pause as
an
emergent phenomenon in the process of distributing the planned rhythm
among the constituents of each syllable. Yann Morlec and Bleike Holm
worked on trainable prosodic model able to recover and generate
elementary multiparametric prosodic contours from the observation of
multiple occurences thanks to statistical modelling. The trainable SFC
(Superposition of Functional Contour) model was confronted to several
languages (French, German, Spanish, Chinese, etc.) and various
linguistic content including spoken maths.For further reading:
- Bailly, G. and Holm, B. (2005) SFC: a trainable prosodic model. Speech Communication,46 (3-4). Special issue on Quantitative Prosody Modelling for Natural Speech Description and Generation - Edited by K. Hirose, D. Hirst and Y. Sagisaka): 348-364.
- Bailly, G. and B. Holm (2002). Learning the hidden structure of speech: from communicative functions to prosody. Cadernos de Estudos Linguisticos, 43: 37-54.
- Morlec, Y., G. Bailly and V. Aubergé (2001). Generating prosodic attitudes in French: data, model and evaluation. Speech Communication, 33(4): 357-371.
Together
with Denis Beautemps, Pierre Badin and Thoams Hueber, we develop speech
technologies
that can help people with temporary or permanent motor or perceptual
deficits or disabilities to communicate. These constraints may be due
to cognitive or physiological handicaps of the interlocutors
themselves, to impoverished communication channels or to adverse
environnements. These technologies aim at enhancing, enriching or
replacing the degraded communication signals with enhanced synthetic
signals thanks to the priori knowledge of the intrinsic coherence of
the multimodal signals. Potential sources of coherence comprise generic
virtual talking heads that can be adapted to the speaker
characteristics as well as linguistic constraints that can
used
in the restauration process when the language being spoken is known.
Such technologies include cued speech synthesis and recognition,
acoustic-to-articulatory inversion, voice conversion. With
Hélène Loevenbrück and in collaboration
with Tomoki
Toda from NAIST, Viet-Anh Tran has proposed an enhanced system
for
murmur-to-speech conversion with an application to silent speech
communication. With Pierre Badin and in the framework of the ARTIS
project, Atef Ben Youssef is working on data-driven statistical
audiovsiual-to-articulatory inversion for language training.For further reading:
- Hueber T. and G. Bailly (2015) "Statistical Conversion of Silent Articulation into Audible Speech using Full-Covariance HMM", Computer, Speech and Language, 36: 274–293.
- Heracleous P., P. Badin, G. Bailly and N. Hagita (2011) "A pilot study on augmented speech communication based on Electro-Magnetic Articulography", Pattern Recognition Letters, 32: 1119-1125.
- Badin P., Y. Tarabalka, F. Elisei & G. Bailly (2010) "Can you read tongue movements? Evaluation of the contribution of tongue display to speech understanding", Speech Communication - special issue on Speech and Face-to-Face Communication, 52(3): 493-503.
- Bailly, G., Badin, D. Beautemps & F. Elisei (2010). Speech technologies for augmented communication, in Computer-Synthesized Speech Technologies: Tools for Aiding Impairment. J. Mullenix and S. Stern. Hershey, PA, IGI Global: 116-128.
- Tran V.-A., G. Bailly & H. Loevenbruck (2010) "Improvement to a NAM-captured whisper-to-speech system", Speech Communication - special issue on Silent Speech Interfaces, 52(4): 314-326.
Grenoble Images Parole Signal Automatique laboratoire
UMR 5216 CNRS - Grenoble INP - Université Joseph Fourier - Université Stendhal