A Spectral Glottal Flow Model for the Source-Filter Separation of Speech
GFM-IAIF (Glottal Flow Model based Iterative Adaptive Inverse Filtering) is a new method that allows to disentangle the contributions of the vocal tract and the glottis in a speech signal, by representing them as two LP filters. Then, using inverse filtering allows to obtain an estimation of the glottal signal, or the excitation signal from speech. Also, modification of the filter and re-synthesis is an easy way for voice modification as demonstrated by the GFM-Voc framework.
Related publication
- O. Perrotin, I. McLoughlin (2019)
A Spectral Glottal Flow Model for Source-Filter Separation of Speech
Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, May 12-17, pp. 7160-7164. (poster)
Source code
The source code for the GFM-IAIF framework is available on GitHub.
Demonstration
The GFM-IAIF framework is implemented in the realtime voice modification system GFM-Voc.The following is based on the oral presentation at ICASSP (see poster).
Estimation of a wideband glottis filter
The estimation of glottal flow from a speech waveform is an essential technique used in speech analysis and parameterisation [1]. Significant research effort has been addressed at separating the first vocal tract resonance from the glottal formant (the low-frequency resonance that describes the open-phase of the vocal fold vibration), but few methods are capable of estimating the high-frequency spectral tilt, characteristic of the closing phase of the vocal fold vibration (which is crucial to the perception of vocal effort). This paper proposes an improved Iterative Adaptive Inverse Filtering (IAIF) method [3] based on a Glottal Flow Model, which we call GFM-IAIF. The proposed method models the wide-band glottis response, incorporating both glottal formant and spectral tilt characteristics [2]. Evaluation against IAIF and recently proposed IOP-IAIF [4] shows that, while GFM-IAIF maintains good performance on vocal tract modelling, it significantly improves the glottis model. This ensures that timbral variations associated to voice quality can be correctly attributed and described.
Model of voice production
Linear model of voice production
Speech communication combines linguistic attributes to convey phonetic information through articulation, and prosodic attributes that encode speech expression through variation of pitch, intensity, rhythm and timbre. The widely used linear source filter model [5] combines those components in four parts; an excitation E, vocal tract (VT) filter V, lip radiation filter L and glottis component G to yield speech:
S(f) = E(f)G(f)V(f)L(f).
The role of G is to model the vibration shape of the vocal folds to convey voice quality. It is often combined with L (a derivation) into a glottal flow derivative (GFD).
A spectral glottal flow model (GFM)
The GFM method is built on the assumption that the glottal component G can be modelled as a third order filter [2]. Figure 1 shows the well-known LF model [6] of the glottal flow (top-left), its derivative (bottom-left), and the glottal flow derivative (GFD) frequency response (right). We can see that the glottal flow period is asymmetric, with a slow opening phase of the vocal folds, responsible for a spectral resonance called ‘glottal formant’, and a more abrupt closing phase contributing to the higher spectral frequencies. These observations motivate a 3rd order spectral model of glottal flow that combines a complex conjugate pole pair accounting for the glottal formant, with one real pole modelling the high frequency attenuation called ‘spectral tilt’. The right panel shows the overlapping of the LF model frequency response (thick black), and the third order filter (thin black) with ±20 dB/decade asymptotes around the glottal formant at FGF and an extra -20 dB/decade attenuation at the cutting frequency FST.
In colours are displayed the glottal flows for a softer voice (blue) and a louder and more tensed voice (green then red). In the temporal domain, a tenser and louder voice lead to a more asymmetric glottal flow and a sharper closure of the vocal folds, respectively. In the frequency domain, these correlates to a higher and wider glottal formant, and a higher spectral tilt cutting frequency FST, respectively. Since such changes of voice quality are well described by only three parameters in the frequency domain (glottal formant position FGF and bandwidth BGF, and spectral tilt cutting frequency FST), we assume that modelling the glottis with a third order filter allows the extraction of glottis parameters that encode well voice quality information.
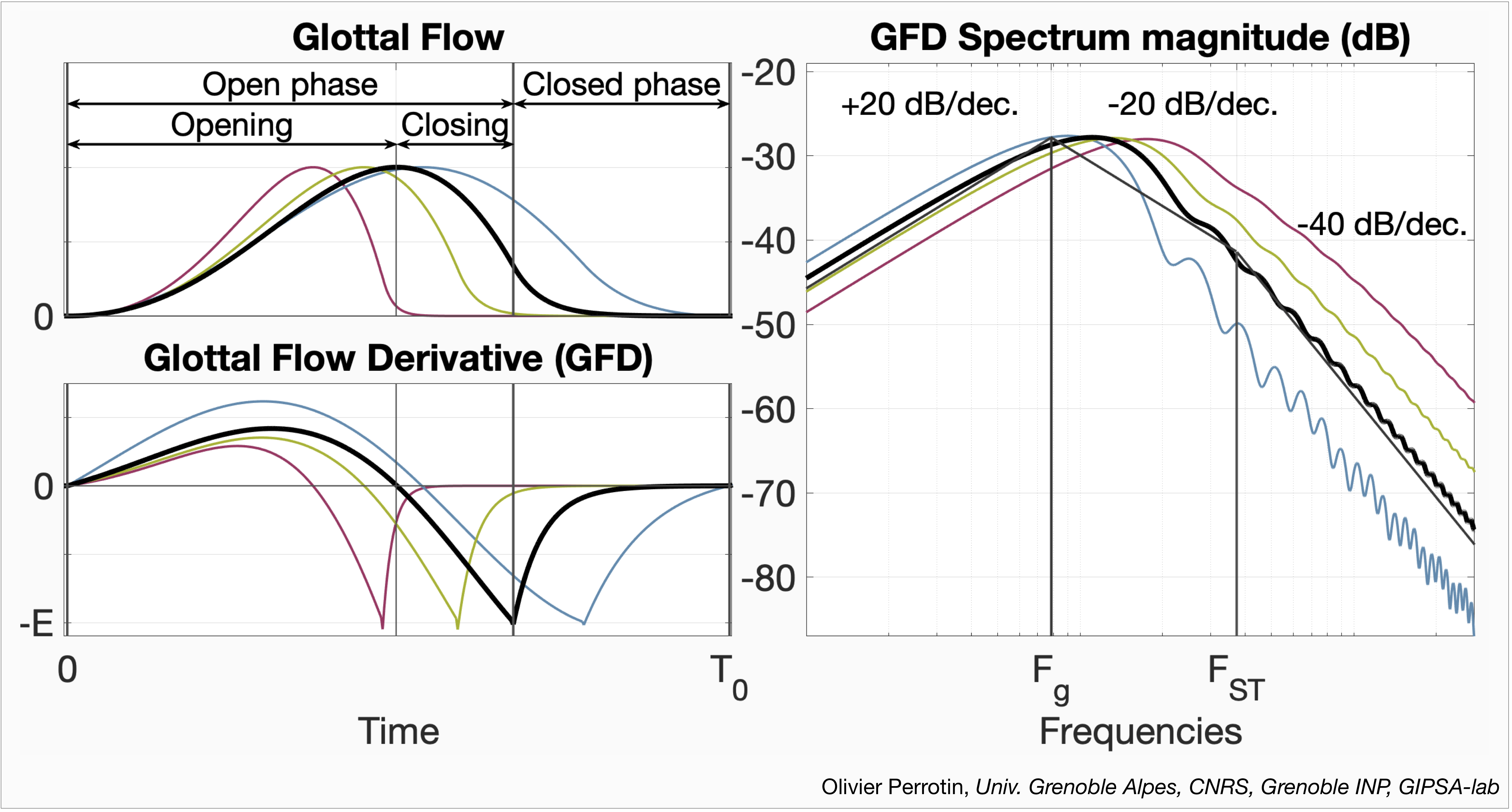
Figure 1: LF model
IAIF-based algorithm
IAIF principle
The IAIF (Iterative Adaptive Inverse Filtering) framework [3] consists in successively estimating the glottis and the vocal tract LP envelopes of a speech signal as described by the four following steps:
- Gross estimation of glottis spectral envelope
-
Remove estimated glottis contribution
Gross estimation of VT spectral envelope -
Remove estimated vocal tract
Fine estimation of glottis spectral envelope G -
Remove estimated glottis contribution
Fine estimation of VT spectral envelope V
Figure 2 illustrates these four steps. Step 1 enables removal of the glottis spectral tilt contribution from the speech signal, in preparation for VT estimation. It is essential in this step not to model any VT formants. Estimation is therefore accomplished by successive 1st order LPC iterations. In VT gross estimation (step 2), the gross glottis and lip radiation filters are deconvolved from the original signal, and VT autoregressive coefficients estimated through high order LPC. Next, fine estimation of the glottis (step 3) first removes lip radiation and the estimated VT contributions (hence all VT formants) from the speech signal. From this, the full spectral envelope of the glottis is extracted. The latter is removed a last time from the speech signal with the lip radiation filter for VT fine estimation (step 4). The glottal flow derivative is finally obtained by deconvolving the fine VT from the speech signal.

Figure 2: Iterations of the IAIF framework
Three IAIF-based methods
Three versions of IAIF have been proposed:
They differ in the LPC orders used for both gross and fine glottis estimation, and summarised in Table 1.
| Gross glottis estimation | Fine glottis estimation | |
|---|---|---|
| Standard IAIF | 1st order LPC Pre-emphasis |
Nth order LPC Manually optimised |
| IOP-IAIF | M x 1st order LPC Until the spectrum is flat |
Nth order LPC Manually optimised |
| GFM-IAIF | 3 x 1st order LPC w.r.t. glottal flow model |
3rd order LPC w.r.t. glottal flow model |
Table 1: Parameters used by the three IAIF-based methods
Regarding gross glottis estimation, standard IAIF uses a 1st order LPC called pre-emphasis. In this case, the glottis filter is reduced to the glottal formant contribution, and assuming that the L filter compensates part of the glottal formant, a simple first-order high-pass filter is used to remove the contribution of GL.
To allow the inclusion of spectral tilt in the glottis filter, IOP-IAIF repeats the pre-emphasis step as many times as necessary to remove all the slope of the speech frame spectrum. The use of successive 1st order LPC iterations allows not to detect a vocalic formant during gross glottis estimation.
Finally, while the IOP-IAIF improvements are merited, we believe that a high filter order risks endowing the glottal model with too much complexity. Instead, we propose to repeat the pre-emphasis step only three times, leading to a 3rd order filter, based on strong evidence that this degree of complexity is sufficient to model the glottis, as detailed in the previous section.
Regarding fine glottis estimation, both IAIF and IOP-IAIF use an LPC order that is manually optimised. Again, based on evidence that a 3rd order filter is enough to encompass most glottis-related timbral variations, we also use a 3rd order filter during this step, providing a glottis filter with a small set of intuitive coefficients.
GFM-IAIF framework
Finally, the full GFM-IAIF framework is displayed in Figure 3. The four steps of the IAIF framework are described, as well as the gross glottis estimation with 3 successive 1st order filters. One can note that since all inverse filtering steps are linear processes, it is also possible to remove the lip radiation contribution once at the beginning, and use the signal without this contribution for the remaining of the process.

Figure 3: GFM-IAIF framework
Evaluation
All three methods have been evaluated on both synthetic and natural speech, on various vowels and different voice qualities (from soft to loud), and male and female speakers. All the details for evaluation can be found in the paper, and the main results are:
- Consistent variations of estimated glottis parameters with voice quality between synthetic and natural speech
- For estimation of glottis parameters related to glottal formant (low-frequencies):
- - Similar performances between methods
-
For estimation of glottis parameters related to spectral tilt (high-frequencies):
- - GFM-IAIF closest to ground truth and more discriminative parameters for voice quality
- - IOP-IAIF and IAIF tend to attribute too much and not enough spectral tilt, respectively
Conclusion
This paper has presented and explored a new proposed method for glottal inverse filtering, GFM-IAIF, which ensures a third order filter in the pre-emphasis step, motivated by spectral glottis source models. Evaluation against standard IAIF and the recently-proposed IOP-IAIF on both synthetic and natural speech showed that while the low frequency region is equally well extracted by the three methods, the choice of a third order filter derived from GFM led GFM-IAIF to provide the best estimation of both glottal formant and spectral tilt relative to voice quality variation. The performance gain is stronger at high frequencies, matching expectations from the literature [2].
GFM-IAIF has been shown to provide good discrimination with vocal quality, and it provides an intuitive way to describe voice quality as well as matching the input parameters of glottal-source synthesis models. We aim to conduct further evaluation on those parameters in future.
References
Glottal source processing: From analysis to applications
Computer Speech & Language, 28(5), pp. 1117–1138.
The spectrum of glottal flow models
Acta Acustica united with Acustica, 92(6), pp. 1026–1046.
Glottal wave analysis with pitch synchronous iterative adaptive inverse filtering
Speech Communication, 11(2-3), pp. 109–118.
Estimation of the glottal flow from speech pressure signals: Evaluation of three variants of iterative adaptive inverse filtering using computational physical modelling of voice production
Speech Communication, 104, pp. 24–38.
Acoustic Theory of Speech Production
Mouton.
The LF-model revisited. transformations and frequency domain analysis
Quarterly Progress and Status Report 2-3, Royal Institute of Technologies - Dept. for Speech, Music and Hearing.
Grenoble Images Parole Signal Automatique laboratoire
UMR 5216 CNRS - Grenoble INP - Université Joseph Fourier - Université Stendhal