Mes activités de recherche portent sur le traitement automatique de la parole, avec un intérêt particulier pour la capture, l'analyse et la modélisation des gestes articulatoires et des signaux électrophysiologiques impliqués lors de sa production. Mes travaux se divisent en deux axes: (1) le développement de technologies vocales qui exploitent ces différents signaux, pour la reconnaissance et la synthèse de la parole, à destination des personnes présentant un trouble de la communication parlée, et (2) l'étude, par le biais de la modélisation et de la simulation, des mécanismes cognitifs qui sous-tendent la perception et la production de la parole, et notamment l'apprentissage auto-supervisé des représentations sensori-motrices.
Axe 1 : Technologies de suppléance vocale et d'aide à la rééducation orthophonique
Interface
de communication en parole silencieuse
Lobjectif est ici de concevoir un système capable de saisir et d'interpréter une parole normalement "articulée" mais "non-vocalisée". Le locuteur met en mouvement ses différents articulateurs (mâchoire, langue, lèvres, voile du palais) mais il nenvoie pas dair dans ses cavités orale et nasale ; il német donc (pratiquement) aucun son. Le principe dune "interface de communication en parole silencieuse" (ou silent speech interface en anglais) est (1) de capturer les indices "inaudibles" de cette "parole silencieuse", comme par exemple le mouvements des articulateurs ou lactivité nerveuse et musculaire, et (2) de les transformer soit en une séquence de mot (reconnaissance), soit directement, et en temps-réel en un signal de parole "audible". Les applications visées sont l'aide aux personnes laryngectomisées et aux personnes atteintes d'une maladie Une maladie neurodégénérative pouvant conduire à une perte de la communication orale. Lapproche que jétudie principalement est basée sur la saisie de lactivité articulatoire par imagerie ultrasonore (échographie) et vidéo, et son traitement à l'aide de technique d'apprentissage automatique (machine learning) et de synthèse sonore.
![]() Tatulli,
E., Hueber, T.,, "Feature
extraction using multimodal convolutional neural networks for
visual speech recognition", Proceedings of IEEE ICASSP, New
Orleans, 2017, pp. 2971-2975.
Tatulli,
E., Hueber, T.,, "Feature
extraction using multimodal convolutional neural networks for
visual speech recognition", Proceedings of IEEE ICASSP, New
Orleans, 2017, pp. 2971-2975.
![]() Hueber,
T., Bailly, G. (2016), Statistical
Conversion of Silent Articulation into Audible Speech using
Full-Covariance HMM, Computer Speech and Language, vol. 36,
pp. 274-293 (preprint
pdf).
Hueber,
T., Bailly, G. (2016), Statistical
Conversion of Silent Articulation into Audible Speech using
Full-Covariance HMM, Computer Speech and Language, vol. 36,
pp. 274-293 (preprint
pdf).
![]() Bocquelet
F, Hueber T, Girin L, Savariaux C, Yvert B (2016)
Real-Time Control of an Articulatory-Based Speech Synthesizer
for Brain Computer Interfaces. PLOS Computational Biology
12(11): e1005119. doi: 10.1371/journal.pcbi.1005119
Bocquelet
F, Hueber T, Girin L, Savariaux C, Yvert B (2016)
Real-Time Control of an Articulatory-Based Speech Synthesizer
for Brain Computer Interfaces. PLOS Computational Biology
12(11): e1005119. doi: 10.1371/journal.pcbi.1005119
Synthèse vocale "incrémentale
Les systèmes de synthèse de la parole à partir du texte (Text-to-Speech ou TTS) ont aujourd'hui atteint une qualité suffisante pour être déployés dans des applications tout public et être utilisé par des personnes ayant perdu l'usage de leur voix. Cependant, un synthétiseur TTS classique fonctionne à l'échelle de la phrase: l'analyse du texte et la synthèse sonore sont déclenchées à chaque fois que l'utilisateur a terminé la saisie d'une phrase complète. La connaissance des limites de début et de fin de phrase est importante pour son analyse linguistique, notamment pour déterminer sa structure syntaxique, qui est importante pour determiner la prosodie, c'est-à-dire la "mélodie" de la voix de synthèse. Cependant, cette synthèse "phrase-à-phrase" introduit une latence importante (proportionnelle à la longueur de la phrase) qui peut être à l'origine d'une certaine frustration pour le destinataire de la communication alors contraint d'attendre la fin de la saisie de chaque phrase pour comprendre et réagir aux propos de son interlocuteur. La synthèse vocale incrémentale vise à améliorer l'interactivité d'une communication orale effectuée par l'intermédiaire d'un TTS, en délivrant, au fur et à mesure de la saisie du texte, une parole de synthèse à la qualité proche de celle obtenue à l'aide d'un TTS classique (travaillant à l'échelle de la phrase). La synthèse vocale "accompagne" la saisie du texte (voir figure ci-après, extraite de la thèse de Maël Pouget). Une approche consiste à exploiter les modèles de langage neuronaux (de type GPT) pour prédire le futur de l'entrée textuelle et d'intégrer cette prédiction dans le système de synthèse vocale (thèse de Brooke Stephenson).

![]() Stephenson
B., Hueber T., Girin. L., Besacier., "Alternate Endings:
Improving Prosody for Incremental Neural TTS with Predicted
Future Text Input", Proc. of Interspeech, 2021, accepted for
publication, to appear (preprint)
Stephenson
B., Hueber T., Girin. L., Besacier., "Alternate Endings:
Improving Prosody for Incremental Neural TTS with Predicted
Future Text Input", Proc. of Interspeech, 2021, accepted for
publication, to appear (preprint)
![]() Stephenson
B., Besacier L., Girin L., Hueber T., "What
the Future Brings: Investigating the Impact of Lookahead for
Incremental Neural TTS", in Proc. of Interspeech,
Shanghai, 2020, to appear (preprint)
Stephenson
B., Besacier L., Girin L., Hueber T., "What
the Future Brings: Investigating the Impact of Lookahead for
Incremental Neural TTS", in Proc. of Interspeech,
Shanghai, 2020, to appear (preprint)
![]() Pouget,
M., Hueber, T. Bailly, G., Baumann, T., "HMM Training Strategy
for Incremental Speech Synthesis", Proceedings of
Interspeech,Dresden, 2015, to appear.
Pouget,
M., Hueber, T. Bailly, G., Baumann, T., "HMM Training Strategy
for Incremental Speech Synthesis", Proceedings of
Interspeech,Dresden, 2015, to appear.
Retour visuel articulatoire (biofeedback)
Cet axe de recherche porte sur le développement d'outils d'aide à la rééducation orthophonique des troubles de l'articulation et sur leur évaluation clinique. L'objectif est de permettre au patient de visualiser ses propres mouvements articulatoires, et notamment ceux de sa langue, dont il n'a généralement pas conscience, pour mieux les corriger. Une première approche utilise l'échographie : le patient visualise ses mouvements de langue et les compare en temps-réel à un mouvement cible qu'il cherche à imiter. Ce protocole a été évalué dans le cadre de la prise en charge des troubles post-glossectomie (étude Revison, collaboration CHU Lyon, DDL, et Centre médical Rocheplane), et des AVC (collaboration avec le LPNC).
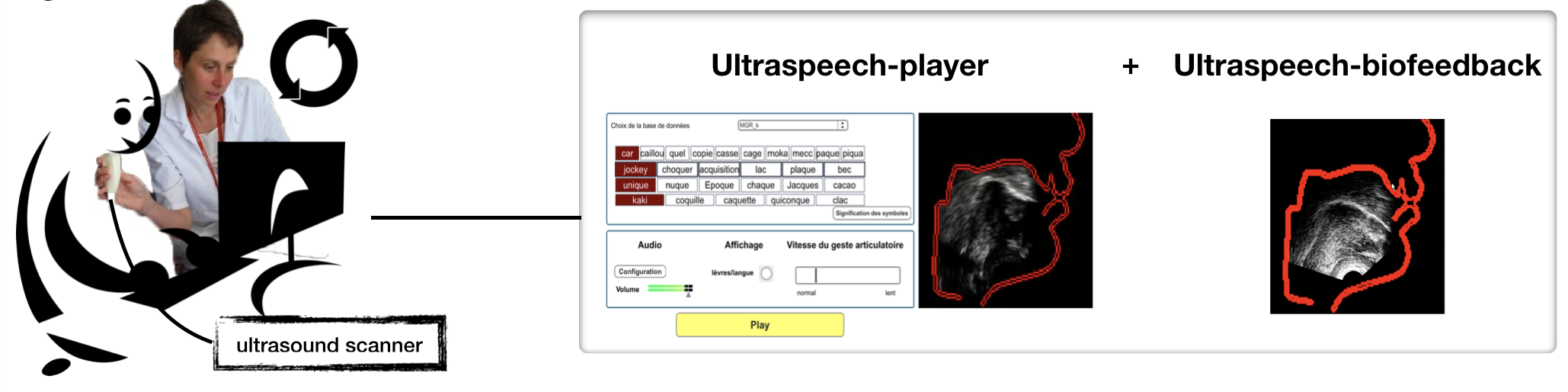
![]() Girod-Roux,
M., Hueber, T., Fabre, D., Gerber, S., Canault, M., Bedoin, N.,
Acher, A., Beziaud, N., Truy, E., Badin, P., Rehabilitation
of speech disorders following glossectomy, based on,
ultrasound visual illustration and feedback", Clinical
Linguistics & Phonetics, doi: 10.1080/02699206.2019.1700310
(preprint).
Girod-Roux,
M., Hueber, T., Fabre, D., Gerber, S., Canault, M., Bedoin, N.,
Acher, A., Beziaud, N., Truy, E., Badin, P., Rehabilitation
of speech disorders following glossectomy, based on,
ultrasound visual illustration and feedback", Clinical
Linguistics & Phonetics, doi: 10.1080/02699206.2019.1700310
(preprint).
![]() Haldin
C., Loevenbruck H., Hueber T., Marcon V., Piscicelli C., Perrier
P., Chrispin A., Pérennou D., Baciu M., (2020) Speech
rehabilitation in post-stroke aphasia using visual
illustration of speech articulators: A case report study,
Clinical Linguistics & Phonetics, DOI:
10.1080/02699206.2020.1780473 (preprint)
Haldin
C., Loevenbruck H., Hueber T., Marcon V., Piscicelli C., Perrier
P., Chrispin A., Pérennou D., Baciu M., (2020) Speech
rehabilitation in post-stroke aphasia using visual
illustration of speech articulators: A case report study,
Clinical Linguistics & Phonetics, DOI:
10.1080/02699206.2020.1780473 (preprint)
La seconde approche vise à s'affranchir d'un appareil d'imagerie par échographie, qui est couteux, et utilise des techniques de traitement du signal, d'apprentissage automatique (machine learning) et de synthèse 3D pour animer automatiquement une tête parlante articulatoire, c'est-à-dire un avatar 3D permettant de visualiser l'intérieur du conduit vocal, uniquement à partir de la voix de l'utilisateur, et en temps-réel.
![]() Hueber,
T., Girin, L., Alameda-Pineda, X., Bailly, G. (2015), "Speaker-Adaptive
Acoustic-Articulatory Inversion using Cascaded Gaussian
Mixture Regression", in IEEE/ACM Transactions on Audio,
Speech, and Language Processing, vol. 23, no. 12, pp. 2246-2259
(preprint
pdf, source
code)
Hueber,
T., Girin, L., Alameda-Pineda, X., Bailly, G. (2015), "Speaker-Adaptive
Acoustic-Articulatory Inversion using Cascaded Gaussian
Mixture Regression", in IEEE/ACM Transactions on Audio,
Speech, and Language Processing, vol. 23, no. 12, pp. 2246-2259
(preprint
pdf, source
code)
Axe 2: Apprentissage auto-supervisé des représentations de la parole
L'objectif est d'extraire automatiquement à partir d'une grande quantité de données audio (ou audiovisuelles), des dimensions latentes qui soient interprétables au niveau perceptif ou physiologique, pour l'étude des systèmes sonores comme pour le contrôle de la synthèse. Nous nous sommes principalement intéressé aux auto-encodeurs (AE), et plus particulièrement aux auto-encodeurs variationnels (VAE).
Régularisation des dimensions latentes d'un VAE
Dans le cadre d'une collaboration avec l'entreprise Arturia (thèse CIFRE de Fanny Roche), nous nous sommes interessés au contrôle du timbre d'un son synthétique à partir de descripteurs symboliques de haut niveau. Le synthétiseur visé doit par exemple permettre de rendre un son plus "agressif", plus "chaud", etc.. Nous avons proposé une technique basée sur les autoencodeurs variationels VAE dont nous avons contraint les dimensions latentes à s'approcher de dimensions perceptives.
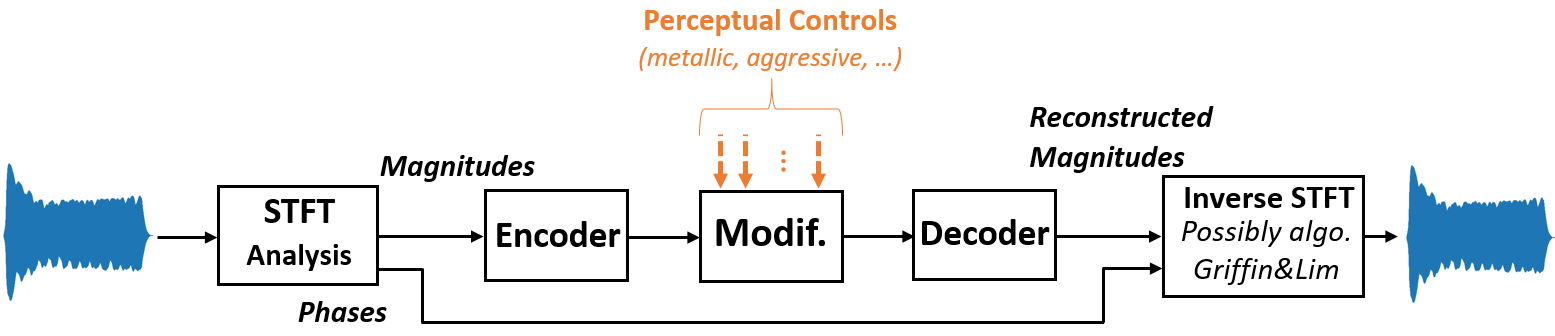
![]() Roche,
F., Hueber, T., Garnier, M., Limier, S., & Girin, L. (2021).
Make That Sound
More Metallic: Towards a Perceptually Relevant Control of the
Timbre of Synthesizer Sounds Using a Variational Autoencoder.
Transactions of the International Society for Music Information
Retrieval, 4(1), pp. 5266.
Roche,
F., Hueber, T., Garnier, M., Limier, S., & Girin, L. (2021).
Make That Sound
More Metallic: Towards a Perceptually Relevant Control of the
Timbre of Synthesizer Sounds Using a Variational Autoencoder.
Transactions of the International Society for Music Information
Retrieval, 4(1), pp. 5266.
![]() Roche,
F.,. Hueber, T., Limier, S, Girin. L., Autoencoders
for music sound modeling : a comparison of linear, shallow,
deep, recurrent and variational models. In Proc. of SMC.
Malaga, Spain, 2019.
Roche,
F.,. Hueber, T., Limier, S, Girin. L., Autoencoders
for music sound modeling : a comparison of linear, shallow,
deep, recurrent and variational models. In Proc. of SMC.
Malaga, Spain, 2019.
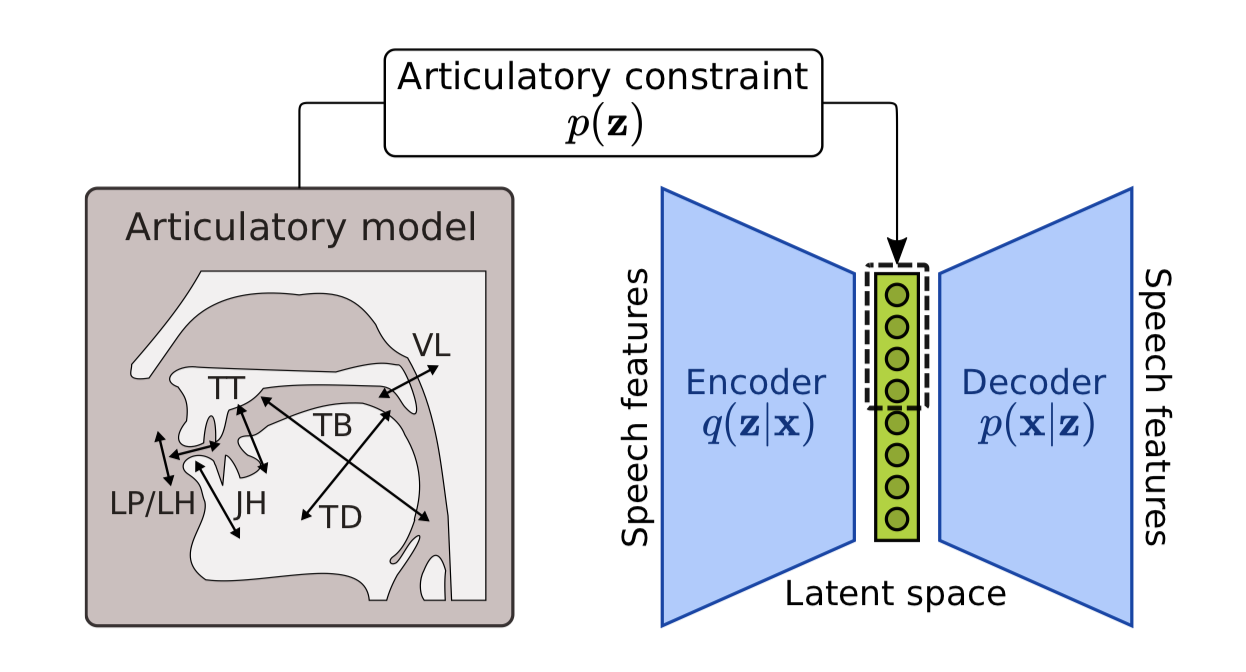 Nous
avons ensuite appliqué cette technique à la parole. Nous nous
sommes intéressés à modéliser le processus de simulation motrice
lors du traitement par le cerveau d'un stimuli auditif. Ici,
l'encodeur du VAE est utilisé pour "projeter" le stimuli auditif
vers un espace latent dont certaines des dimensions sont
contraintes à encoder des informations de nature articulatoire.
Nous avons pu montrer que cette contrainte articulatoire
améliore la vitesse d'apprentissage et la précision du modèle,
et donne de meilleures performances dans une tâche de débruitage
de la parole qu'un VAE non-contraint (Marc-Antoine George's
PhD).
Nous
avons ensuite appliqué cette technique à la parole. Nous nous
sommes intéressés à modéliser le processus de simulation motrice
lors du traitement par le cerveau d'un stimuli auditif. Ici,
l'encodeur du VAE est utilisé pour "projeter" le stimuli auditif
vers un espace latent dont certaines des dimensions sont
contraintes à encoder des informations de nature articulatoire.
Nous avons pu montrer que cette contrainte articulatoire
améliore la vitesse d'apprentissage et la précision du modèle,
et donne de meilleures performances dans une tâche de débruitage
de la parole qu'un VAE non-contraint (Marc-Antoine George's
PhD).
![]() Georges
M-A, Girin L., Schwartz J-L, Hueber, T., "Learning robust speech
representation with an articulatory-regularized variational
autoencoder", Proc. of Interspeech, 2021, pp, 3335-3349 (preprint)
Georges
M-A, Girin L., Schwartz J-L, Hueber, T., "Learning robust speech
representation with an articulatory-regularized variational
autoencoder", Proc. of Interspeech, 2021, pp, 3335-3349 (preprint)
Apprentissage auto-supervisé des relations sensori-motrices
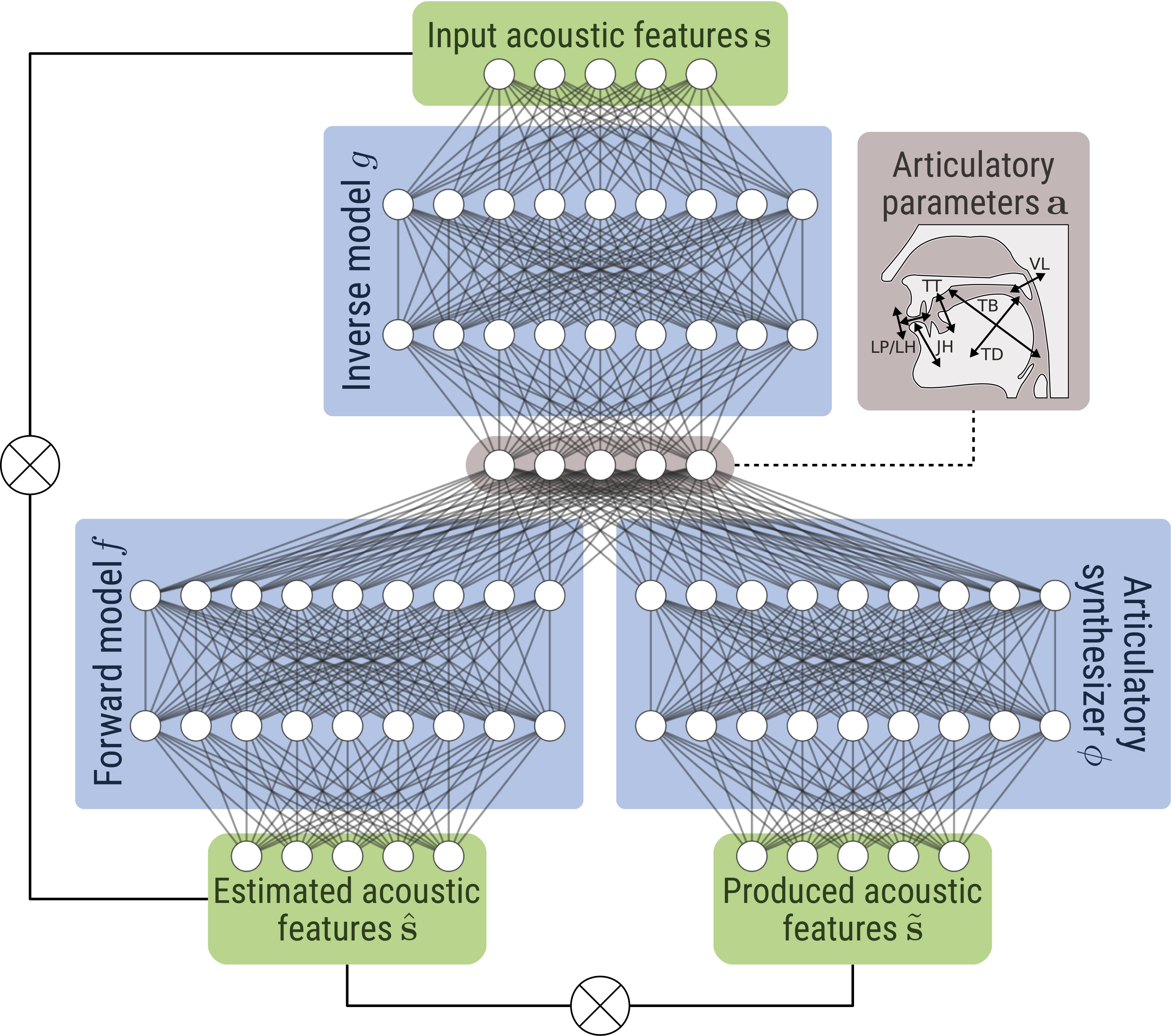
La plupart des systèmes artificiels conçus pour résoudre de façon automatique certaines tâches de perception et de production de la parole, et notamment ceux développés dans mes travaux précédents, exploitent des modèles statistiques dont les paramètres sont généralement estimés par apprentissage automatique strictement supervisé. Cet apprentissage supervisé des liens entre les différents espaces de représentation de la parole (acoustique, articulatoire, linguistique) semble a priori éloigné de la manière dont un humain perçoit, traite et produit de la parole. En particulier, nous nous interessons à la manière dont un enfant apprend la relation entre le son de la parole, et le geste articulatoire associé. Nous développons un agent communiquant, basé sur des techniques d'apprentissage profond, capable d'apprendre ces relations sensori-motrices de façon auto-supervisée, en répétant les stimuli auditifs qu'il perçoit (Marc-Antoine George's PhD).
![]() Georges
M-A, Diard, J., Girin, L., Schwartz J-L, Hueber, T.,
"End-to-end speech motor control based on self-supervised
learning of acoustic-to-articulatory mapping", Proc. of ICASSP,
to appear
Georges
M-A, Diard, J., Girin, L., Schwartz J-L, Hueber, T.,
"End-to-end speech motor control based on self-supervised
learning of acoustic-to-articulatory mapping", Proc. of ICASSP,
to appear
Codage prédictif
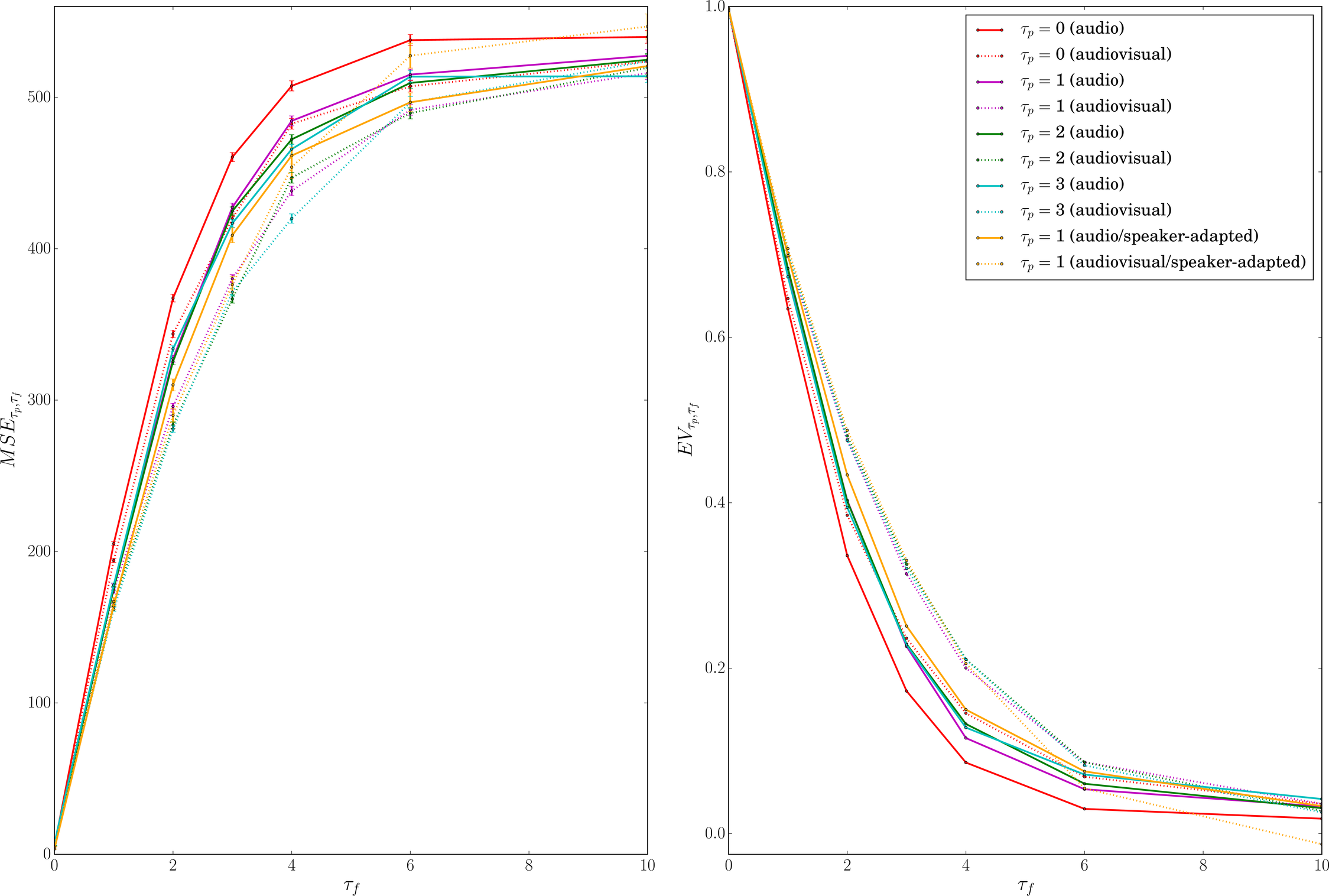 Une
des tâches prétextes pour l'apprentissage auto-supervisé de
représentations est la prédiction du futur d'un signal d'entrée,
à partir de son passé. Ce paradigme, appelé codage prédictif,
est également très présent en sciences cognitives et en
neurosciences. Il suppose que notre cerveau implémente un
algorithme d'inférence en ligne des entrées sensorielles à
venir, à partir des entrées sensorielles passées. Pour la
parole, cette prédiction s'appuierait sur la recherche de
régularités dans le signal acoustique, mais recruterait
également le niveau moteur et le niveau linguistique. A l'aide
de réseaux convolutionnels entrainés sur des larges bases de
données multi-locuteurs, nous avons quantifié l'interet d'une
telle stratégie, pour différent empan temporel (de 25 à 150ms),
pour la parole auditive et audiovisuelle.
Une
des tâches prétextes pour l'apprentissage auto-supervisé de
représentations est la prédiction du futur d'un signal d'entrée,
à partir de son passé. Ce paradigme, appelé codage prédictif,
est également très présent en sciences cognitives et en
neurosciences. Il suppose que notre cerveau implémente un
algorithme d'inférence en ligne des entrées sensorielles à
venir, à partir des entrées sensorielles passées. Pour la
parole, cette prédiction s'appuierait sur la recherche de
régularités dans le signal acoustique, mais recruterait
également le niveau moteur et le niveau linguistique. A l'aide
de réseaux convolutionnels entrainés sur des larges bases de
données multi-locuteurs, nous avons quantifié l'interet d'une
telle stratégie, pour différent empan temporel (de 25 à 150ms),
pour la parole auditive et audiovisuelle.
![]() Hueber,
T., Tatulli, E., Girin, L., Schwartz, J-L., "Evaluating
the potential gain of auditory and audiovisual speech
predictive coding using deep learning", Neural
Computation, vol. 32 (3), to appear (preprint,
source code,
dataset/pretrained
models)
Hueber,
T., Tatulli, E., Girin, L., Schwartz, J-L., "Evaluating
the potential gain of auditory and audiovisual speech
predictive coding using deep learning", Neural
Computation, vol. 32 (3), to appear (preprint,
source code,
dataset/pretrained
models)