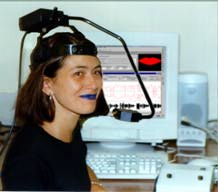
Version en-ligne : http://www.gipsa-lab.inpg.fr/~frederic.elisei/TV/ du 28/06/2000
En analysant, pour un locuteur donné, son domaine articulatoire en parole naturelle, on peut construire de lui un modèle 3D paramétré par quelques valeurs, liées à des quantités visibles : déplacements de la machoire, déformations des lèvres... Classiquement, un tel modèle pourrait être utilisé en animation pour faire articuler au clone des séquences jamais prononcées par le modèle original.
Parce que ce modèle dédié à un locuteur est suffisamment précis, on va pouvoir l'utiliser pour représenter (transmettre) des images réelles : celles de cette même personne en train de parler devant une caméra. Par la technique d'analyse descendante proposée pour le projet Tempo Valse, on trouvera des valeurs pour les quelques paramètres (2 à 6 selon la précision voulue) du modèle de synthèse qui permettent de coder et donc d'émettre une bonne approximation de chaque image d'une sène de parole naturelle. On préservera alors du message audio-visuel original son lien image/parole, et donc le gain d'intelligibilité associé, ainsi que la ressemblance au locuteur. Ce même modèle (fixé une fois pour toutes), avec ces paramètres qui varient dans le temps sont utilisés par le terminal récepteur pour synthétiser en temps réel une image du correspondant distant, même à travers un réseau à très bas débit.
Typiquement, les images des correspondants seraient obtenues à l'aide d'une micro-caméra, qui filme le locuteur depuis une vue rapprochée, comme sur la figure précédente.
Le modèle articulatoire, une fois texturé et synthétisé, peut cependant donner des représentations plus étendues, comme sur la figure ci-dessous.

Images de clones texturés, sans dents de synthèse
Pour chaque locuteur, c'est par une nouvelle analyse statistique de positions articulatoires prototypiques, que l'on va créer un modèle qui lui soit propre, et dont les paramètres de contrôle correspondront effectivement à des commandes articulatoires. Ces paramètres ont une action linéaire, pour mettre en mouvement les points 3D (du visage, des lèvres) qui constituent le modèle. Cette collection de points, qui sera par la suite organisée en réseau de facettes et texturé pour les besoins de la synthèse, peut être vue comme la combinaison linéaire de quelques modèles statiques (typiquement, un modèle moyen "au repos" et 2 à 6 modèles "en situation").

Dans le cadre du système LipsInk de Ganymedia, on trouve un modèle articulatoire simple, commandé par 2 paramètres : la largeur et la hauteur de la bouche (mesurées d'après un flux vidéo où le locuteur a ses lèvres maquillées en bleu). Ainsi, des mascottes ou des logos peuvent être animés en temps-réel :
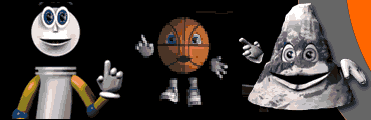
Manifestement, ces paramètres permettent d'animer (de façon plus ou moins impersonnelle) une bouche (l'ouvrir ou la fermer en synchronisation avec le son), mais il manque des informations cruciales pour la parole. En particulier, toutes les positions relatives des dents et des lèvres (liées aux mouvement de la mâchoire) ne peuvent pas être codées. Par la méthode de construction proposée pour le projet Tempo Valse, on va retrouver le besoin de paramètres supplémentaires, construire un modèle plus précis et mesurer la différence, notamment pour un auditeur/spectateur.
Dans cette partie, on explicite l'ensemble de la méthode qui a déjà été utilisée pour créer plusieurs modèles, avec 6 paramètres. Dans le cadre du projet, il est prévu d'étudier un protocole plus léger de création de clones et de génération des modèles articulatoires.
Parce qu'on cherche à créer un modèle articulatoire qui soit fidèle à une personne, sa construction se base sur des mesures 3D et des données images enregistrées. C'est la nature et l'obtention de ces enregistrements qui va tout d'abord être précisée.
Les modèles sont créés lors d'une séance spéciale d'enregistrement vidéo des gestes de parole du locuteur, à qui il est demandé de prononcer 34 phonèmes préétablis : il s'agit de 10 voyelles isolées et de 8 consonnes prononcées dans 3 contextes de voyelle symétrique (VCV), dont on extraira l'image centrale.
![]()
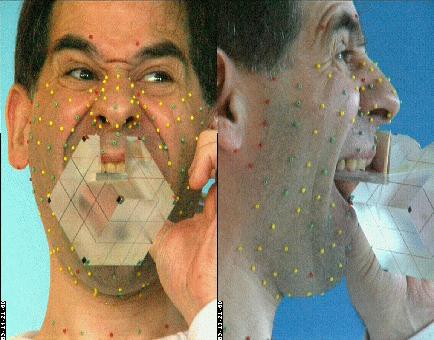
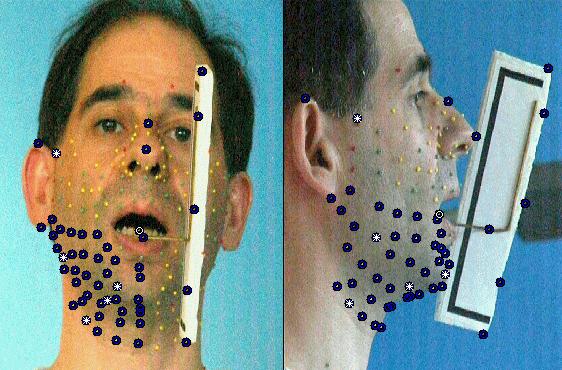
À ce stade du projet, la technique utilisée nécessite que des marqueurs colorés (les petites billes qui apparaissent sur l'image suivante) soient collées sur le visage, et matérialisent donc les déformations du visage.
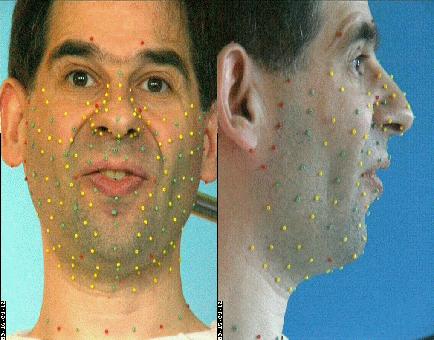
Plus de 180 billes tapissent le locuteur pour la phase de création du modèle articulatoire
Des positions des billes sur les images on déduira les positions (et donc les mouvements) 3D grâce à l'utilisation de caméras calibrées (au moins 2). On utilise pour la calibration un cube monté sur un palet qui permet de le maintenir contre la mâchoire supérieure, de sorte qu'en plus de permettre l'estimation des paramètres des caméras, on définit (taille, position et orientation) un repère privilégié rigidement lié à la tête par sa mâchoire supérieure.
Le cube sert à calibrer les caméras et à définir un repère lié à la mâchoire supérieure
On aura aussi besoin d'inférer un modèle de déplacement de la mâchoire inférieure, qui n'est généralement pas directement visible. À l'aide du dispositif qui apparaît sur la figure suivante (le 'jaw splint', sorte de fer à cheval qui se cale sur les dents de la mâchoire inférieure et est rigide avec une tige qui sort de la bouche et trahit donc les mouvements internes), on rend ses déplacements mesurables pour toutes les configurations. On peut alors enregistrer les coordonnées 3D de marqueurs externes solidaires de la mâchoire inférieure, lors de l'articulation d'un jeu de visèmes (plus restreint que le précédent).
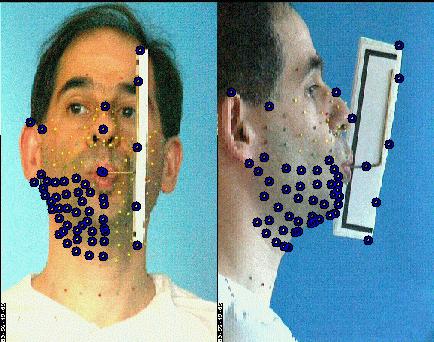
Les billes du dispositif reflètent la position et les mouvements de la mâchoire
À l'occasion de la collecte de ces données 3D qui sont nécessaires à la construction du modèle articulatoire, on enregistre aussi l'apparence visuelle du visage, sans billes, qui servira à texturer le rendu graphique du modèle, pour compléter le modèle articulatoire en un modèle pour la synthèse graphique.
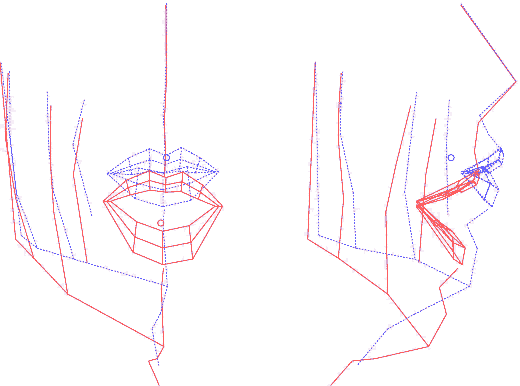
Les coordonnées 3D des points vus dans chaque image doivent être ramenées dans le repère commun lié au cube. Dans ce but, et pour chaque image du corpus, on recherche (par optimisation non linéaire, dans le logiciel Matlab) une combinaison rotation+translation qui transforme les coordonnées de points relativement rigides entre eux (près de la tempe, entre les deux yeux, sur les oreilles et les dents supérieures) à celles de référence.
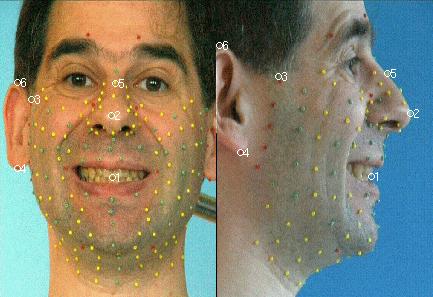
Les points 1,3, 4 et 5 sont suffisament rigides pour servir à réaligner la tête
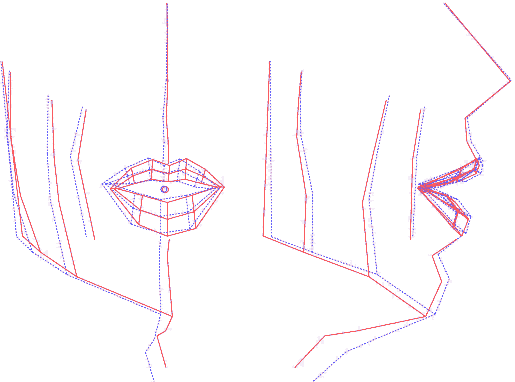
Pour chaque image du corpus articulatoire, on dispose de coordonnées 3D pour les points de chair qui sont matérialisés par les billes. On va compléter ces mesures par des estimations de coordonnées 3D à la surface des lèvres et sur leurs contours. Pour cela, on utilise un modèle de lèvres 3D, générique et déformable qui a été construit à l'ICP.
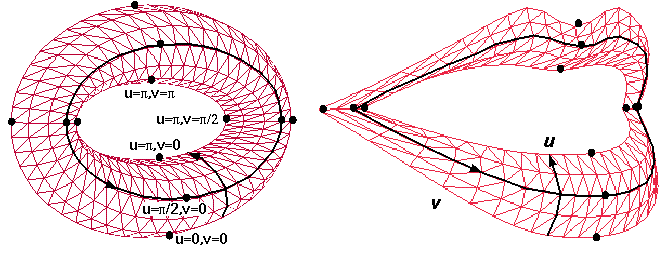
Le modèle 3D paramétrique de lèvres de l'ICP
C'est lui que l'on va adapter (manuellement) sur chaque visème, jusqu'à ce que sa projection suivant le modèle de caméra se conforme au contenu des images (qui sont des contraintes de face et de profils). Comme il s'agit d'un modèle 3D, il sert à générer des points 3D dont les coordonnées s'appliquent aux images de lèvres.
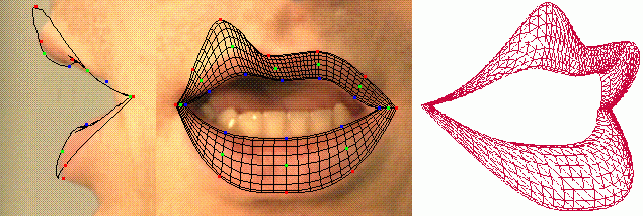
Déformable et adaptable, le modèle 3D de lèvres en cours de placement
Le modèle 3D de lèvres appliqué à différentes postures/locuteurs
Ainsi, on dispose pour chaque visème de nouvelles coordonnées 3D qui viennent s'ajouter à celles des billes. Avant de générer le modèle articulatoire, on va encore rajouter un point supplémentaire, lié à la mâchoire inférieure.
Grâce à l'enregistrement du corpus jaw splint et après correction des mouvements de la tête, on dispose de positions 3D pour un point spécifique de la mâchoire inférieure (dénommé LT, comme 'lower tooth', il est par exemple défini à la jointure des deux incisives) et des points du visage. On cherche à construire un modèle par régression linéaire, qui d'après les coordonnées de quelques points du visage prédise celles de LT. Le choix du modèle consiste à tester les combinaisons de 3,4 ou 5 points du visage pour conserver celle qui produit le minimum d'erreur de prédiction.
Le cercle blanc matérialise LT, et a été prédit à partir des 5 billes réhaussées en blanc.
Une fois ce prédicteur construit, on peut l'appliquer, toujours en parole naturelle, à chaque visème de l'autre corpus avec billes pour obtenir des coordonnées 3D de LT, même quand il n'est pas visible.
On dispose d'une collection (pour chaque visème) de déplacements 3D pour les points matérialisés par les billes, estimés par le modèle de lèvres ou lié à la mâchoire inférieure. Construire un modèle de ces mesures va consister à définir un paramétrage qui les pilote. Le choix s'est porté sur un modèle linéaire, tel qu'il pourrait être créé par une analyse en composantes principales (ACP). Cependant, et c'est une des spécificités de l'approche de l'ICP, on lui préfère l'utilisation d'une ACP guidée : connaissant les causes et conséquences de déformation du visage, on va séquencer le calcul des sous-espaces propres selon un ordre et des zones d'intérêt qui correspondent à des manifestations visibles : on va successivement guider l'apparition d'un mouvement lié aux déplacements de la mâchoire, puis aux déformations des lèvres, et enfin au reste du visage.
Voici les détails de cette opération :
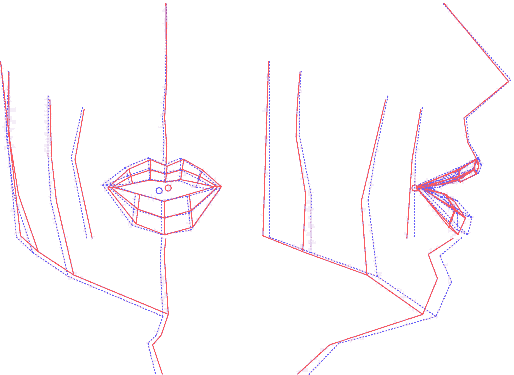
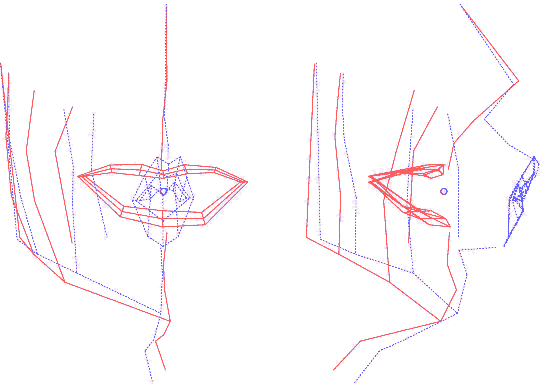
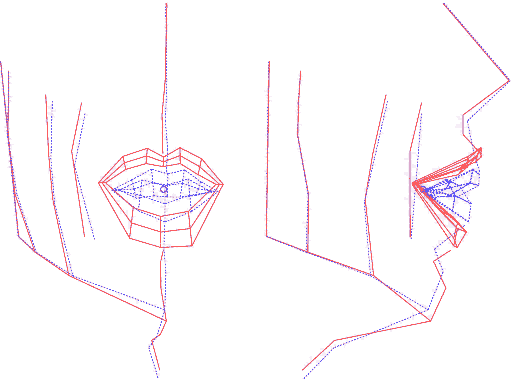
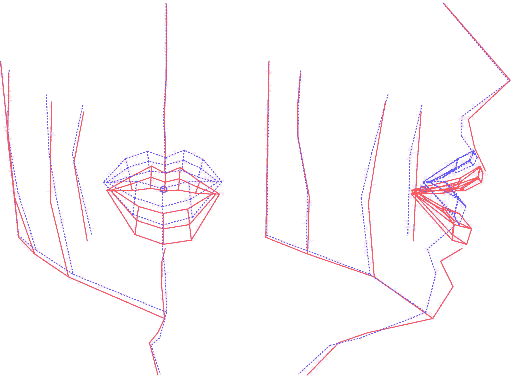
Ainsi construit, le modèle articulatoire permet de générer les coordonnées 3D des points du visage et des lèvres, à partir de la donnée de 6 paramètres, dont l'interprétation est, par construction, articulatoire. En analysant les nomogrammes pour chacun des paramètres, on peut retrouver ces mouvements dominants : ouverture, protrusion et écartement des lèvres, ouverture et avancée de la mâchoire et d'autres mouvements du visage (menton et pomme d'Adam notamment).
Animation (AVI) montrant le mouvement de chaque composante
L'évaluation de la qualité des modèles construits peut être faite à plusieurs niveaux :
À ce stade du rapport, on ne dispose que du modèle articulatoire, pas encore d'un clone complet ; on ne peut donc examiner que les résultats de couverture statistique. Voici les mesures obtenues en termes de variances
|
Variance à la reconstruction |
||
|
Explication |
Explication cumulée |
|
|
Jaw1 |
27.19 % |
27.19 % |
|
Jaw2 |
0.29 % |
27.48 % |
|
Lips1 |
60.23 % |
87.71 % |
|
Lips2 |
5.24 % |
92.95 % |
|
Lips3 |
3.00 % |
95.94 % |
|
Skin1 |
0.84 % |
96.78 % |
Du point de vue statistique, le nombre de paramètres et la procédure de construction préservent apparemment un maximum d'information des données initiales. Il faut cependant se demander si c'est celle qui est nécessaire ou utile au futur spectateur confronté au message restitué par le futur clone. C'est le but de la mesure d'intelligibilité qui est présentée plus loin dans ce rapport.
Dans le cadre du projet Tempo Valse, il est prévu de chercher à créer le modèle articulatoire de façon plus rapide. Par exemple, en essayant d'abaisser le nombre des 34 visèmes actuellement utilisés lors de la phase d'enregistrement. Disposer d'un modèle précis ainsi qu'on l'a construit permettra de faire de telles expériences et de quantifier l'éventuelle perte d'information et d'intelligibilité.
On pourrait aussi envisager de construire un méta-modèle, qui possède deux niveaux de paramètrage : un niveau d'animation articulatoire tel qu'il existe déjà, et un niveau de définition articulatoire, qui spécialiserait les précédents paramètres à un locuteur donné. On imagine qu'un tel méta-modèle devrait être créé en analysant et combinant plusieurs locuteurs, qu'il faudrait choisir avec soin pour obtenir un espace représentatif. C'est seulement avec une procédure plus légère d'acquisition du modèle articulatoire que cette entreprise pourrait devenir réalisable.
Actuellement, une grande partie du modèle articulatoire est aussi utilisée directement comme modèle de rendu : un maillage relie directement les points 3D définis par le modèle linéraire. Seule la zone des lèvres est synthétisée avec plus de polygones, grâce au modèle générique procédural, qui permet de raffiner leur définition jusqu'à la précision voulue.
Dans tous les cas, c'est surtout la texture dont on va habiller ce maillage géométrique qui rendra le modèle ressemblant à un niveau de détail suffisant. En pratique, on a même intérêt à utiliser plusieurs textures, pour couvrir l'apparition de détails de parole qui ne pourraient pas être capturées assez finement par une géométrie de taille raisonnable : le pli qui se matérialise à la frontière intérieure de la joue en est un bon exemple.
La synthèse d'une vue intermédiaire s'apparentera alors à du Morphing 3D : on mélange (technique du Blending) pixel à pixel des images déformées (principe du Warping) selon le modèle articulatoire du locuteur.
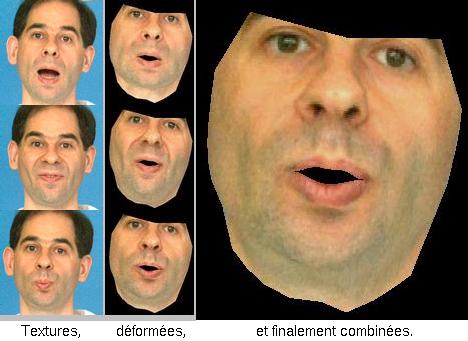
Création d'une nouvelle vue texturée par Morphing 3D multi-référence
Suite au développement du marché du jeu sur PC, ces machines disposent actuellement de cartes graphiques peu onéreuses qui gèrent ces primitives 3D et permettent de calculer facilement et rapidement une image du modèle. La synthèse de modèles 3D animés et texturés n'est donc pas un problème sur ce type de machines cibles. On va donc s'intéresser à la partie plus problématique, celle du choix des textures à utiliser.
Pour des raisons d'efficacité, il n'est bien sûr pas possible d'utiliser un trop grand nombre de textures : celles-ci pourraient ne pas tenir dans la mémoire dédiée de la carte graphique, et il finirait par y avoir trop de passes de rendu, ce qui dégraderait la vitesse de synthèse. De plus, le mélange de textures est susceptible de créer un effet de flou, qu'il est plus facile de contrôler avec un nombre limité de textures. En pratique, 3 à 5 textures semblent être un maximum raisonnable.
On cherche un sous-ensemble des 34 textures qui couvrent au mieux l'espace articulatoire mesuré. Pour cela, on a besoin d'une distance : on utilisera la distance euclidienne, directement sur les coordonnées des points 3D des modèles. Dans le cas où l'on cherche trois visèmes aussi différents que possible, cela revient à maximiser :
![]()
![]()
On retient les trois textures associées à ces visèmes. Dans le cas de notre modèle, il s'agit de ceux-ci :
Les trois textures extrêmes et la configuration de modèle associée
Dans le cas de 3 textures, et pour texturer un visème cible M, on forme une texture combinée, mélangées pixel à pixel selon trois coefficients de la forme :
![]()
Ce paramétrage assure que chacune des textures de définition sera utilisée de façon prépondérante lorsque le modèle approchera la forme associée. Pour conserver la luminosité moyenne des images, et pour que les valeurs calculées pour chaque pixel restent affichables, il faut que ces coefficients soient dans l'intervalle [0,1] et que leur somme reste toujours égale à 1. On force cette dernière contrainte en normalisant leur somme.
Le choix des coeeficients k règle la suprématie d'une texture sur les autres. Pour minimiser les problèmes de flou dans ces situations d'apprentissage, on minimise :
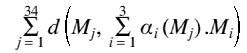
Dans le cadre du projet Tempo Valse, l'angle de vue est naturellement fixé au cas du vis-à-vis, puisque la restitution se fait face au casque. Avec les images des textures d'apprentissage, de face, on est dans d'excellentes conditions pour restituer une image de qualité.
La synthèse d'un visème réalisant un i permet de voir la différence (le gain) qui résulte des textures combinées :

Une mème configuration, sans puis avec texture combinée
On verra plus loin comment ces images pourront être comparées à celle du corpus d'apprentissage, pour quantifier le gain.
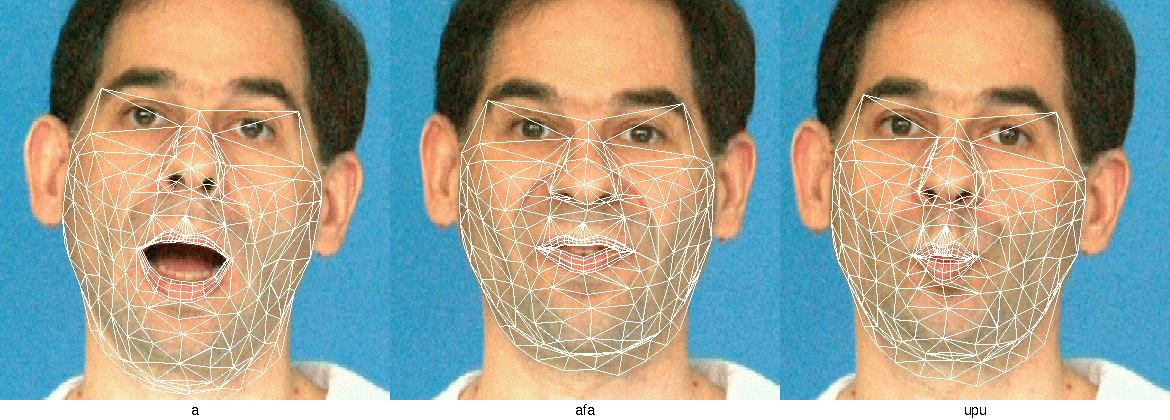
Avec un maillage animé de façon réaliste par le modèle articulatoire et un jeu de texture propre à restituer les détails dynamiques du visage, on est à même de créer des images synthétiques du locuteur qui a servi de modèle. Pour dépasser le cadre de l'image ressemblante, pour que ce clone se comporte dynamiquement comme son modèle et qu'il véhicule le message labial de son alter ego, il va falloir trouver à chaque instant de la séquence de synthèse le bon jeu de paramètres articulatoires.
Effectuer l'analyse, c'est trouver pour les paramètres articulatoires un jeu de valeurs tel qu'une image donnée du locuteur soit approchée au mieux par le modèle de synthèse. Dans le cadre de Tempo Valse, on se donne un modèle (articulatoire, de synthèse) qui correspond au locuteur, et permet d'envisager d'effectuer une analyse, sans maquillage, en situation de télécommunication.
À l'heure actuelle, trois méthodes différentes ont été testées pour effectuer l'analyse dans le cadre du labiophone :
Toutes ces méthodes se basent sur le même schéma d'une boucle d'analyse par synthèse. Avant de détailler les spécificités des trois méthodes, on va rappeler le principe de ce paradigme.
Comme on dispose d'un modèle de synthèse qui est paramétrable, en faisant varier ces paramètres sur toutes les valeurs possibles, on génère un espace d'images. Si le modèle était complet, toutes les images réelles seraient synthétisables. En pratique, ne serait-ce que du fait du faible nombre de paramètres, comparé au nombre de pixels dans l'image, on ne peut que générer une image approchée. Il faut donc quantifier en quoi ces images se ressemblent plus ou moins, malgré leurs différences. À ces notions de distance, on peut associer celle d'erreur de reconstruction.
Puisqu'on ne pourra reconstruire qu'une image approchée, l'image reconstruite qui sera jugée la plus proche peut varier fortement selon le critère d'erreur choisi. Plus que la couleur ou l'aspect de la peau (qui peuvent varier selon l'éclairage ou la pilosité), on cherchera à construire des critères d'erreurs plus invariants, à défaut d'être parfaits, et qui s'intéressent à la position comme à la forme des éléments du visage qui convoient l'information d'intelligibilité.
On cherche une configuration du modèle articulatoire qui reconstruise au mieux l'image originale. En termes algorithmiques, cela revient à trouver les paramètres d'articulation et de position qui minimisent (si possible globalement, et à défaut localement) l'erreur de reconstruction précédente. De nombreuses techniques existent pour résoudre cette classe de problème, mais il faut cependant noter qu'on aurait ici particulièrement intérêt à minimiser le nombre de reconstructions et de calculs d'erreurs (c'est à dire le nombre d'itérations de l'algorithme d'optimisation) car ces étapes sont très coûteuses, du fait de la taille des images manipulées.
Dans les réalisations qui suivent, une approche dichotomique d'exploration de l'espace des paramètres (articulatoires et de position) a été utilisée. Elle pénalise bien sûr le temps d'exécution, mais il est prévu, pendant le déroulement du projet, de tester d'autres stratégies et algorithmes d'optimisation, et notamment celui du Simplexe.
Comme les lèvres sont un élément clé de la parole visible, on peut souhaiter qu'elles constituent l'ancrage privilégié pour la synthèse du modèle. Il est alors naturel de chercher une erreur qui se focalise sur la position reconstruite des lèvres, et l'adéquation de sa forme avec celle estimée sur l'image caméra.
Cette première méthode d'analyse consiste à se concentrer sur la légère différence chromatique entre la peau et les lèvres de chaque image en provenance de la caméra. Chaque pixel vidéo se voit affecté d'une probabilité d'être un point de lèvres, et pourra moduler positivement (ou négativement) le critère d'erreur de reconstruction s'il est couvert par une partie lèvres (ou respectivement, par une partie peau) du modèle articulatoire projeté.
On considère qu'existent deux classes, suffisamment séparables, qui recouvrent les points des lèvres (classe 'vermillon') et les autres points du visage (notamment la peau autour des lèvres).
Actuellement, ces deux classes sont initialisées en spécifiant à la souris des zones disjointes qui les représentent. Si l'on note ![]() le nombre de pixels du vermillon, et
le nombre de pixels du vermillon, et ![]() le nombre de pixels de l'autre classe, on peut construire le vecteur discriminant :
le nombre de pixels de l'autre classe, on peut construire le vecteur discriminant :
![]()
où
![]() si l'échantillon i appartient à la classe vermillon,
si l'échantillon i appartient à la classe vermillon, ![]() sinon.
sinon.
.
On peut alors définir une probabilité qu'un pixel appartienne à la classe vermillon :
![]()
avec ![]() la moyenne et l'écart type de
la moyenne et l'écart type de ![]() pour les pixels vermillon de l'apprentissage.
pour les pixels vermillon de l'apprentissage.
Le modèle articulatoire recouvre la zone des lèvres et une bande de peau autour d'elles. Lorsqu'on projette le modèle sur une image caméra, on souhaite obtenir un score qui soit d'autant meilleur qu'il y a adéquation entre la prédiction (projection de ces zones) et la réalisation (probabilité calculée pour chaque pixel).
"image lèvres+bande de peau"
L'erreur de reconstruction qui a été utilisée est :
![]()
Image de probabilités lèvres/peau
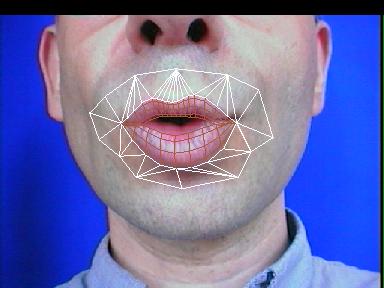
Le modèle local trouvé par l'analyse, superposé à son image cible
La méthode précédente, en privilégiant les lèvres dans le critère d'erreur, en fait une cible privilégiée. Ainsi, sans avoir pourtant exprimé une contrainte explicite sur les contours, ceux-ci sont généralement atteints par le modèle déformable.
Dans un cas plus général, on souhaite utiliser un modèle de visage plus vaste que celui du proche voisinage des lèvres : dès lors, il semble raisonnable de penser que le prétraitement statistique, en plus de rehausser le contraste lèvre/peau, va aussi affaiblir ou masquer des informations de couleur ou de texture qui étaient sur l'image caméra : un grain de beauté, ou une ride de parole, sont pourtant des éléments dont on voudrait qu'ils servent d'ancres pour l'analyse, sans avoir à exprimer a priori qu'ils sont présents sur l'image (comme pour les lèvres) si l'on veut que la procédure puisse être répétée sur d'autres locuteurs.
La solution à ce problème passe probablement par l'utilisation de la texture (des textures) du modèle, qui inclut les éléments spécifiques au locuteur. Deux expériences ont déjà été réalisées pour évoluer vers une solution plus satisfaisante :
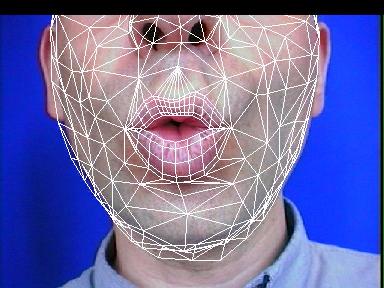
Un modèle mis en correspondance par la dernière méthode
Avec une texture et une procédure d'analyse, il devient possible de comparer, pour les images du corpus d'apprentissage, l'image reconstruite avec l'image originale. Une image de différence visualise les zones où une erreur, systématique ou résiduelle, apparaîtrait. On mesure ainsi l'apport, ne serait-ce que pour la synthèse, des textures multiples (notamment pour le pli joue/bouche).
"image de diff. du i"
Dans le cas d'images caméras quelconques, cette comparaison n'est pas exploitable, du fait des différences précédemment évoquées (lumière...). On peut par contre avoir recours aux tests d'intelligibilité introduits plus tôt dans ce rapport pour quantifier la qualité des reconstructions fournies par la synthèse après analyse/synthèse d'une séquence audio-visuelle.
L'un des tous premiers modèles construits ne comportait qu'un demi-visage (avec les lèvres complètes, mais maquillées en bleu à l'époque) et où la seule texture disponible inclut les billes. Pour ce modèle, on dispose déjà des résultats de mesures d'intelligibilité.
"tableau des résultats d'intelligibilité"
Pour les nouveaux modèles construits (visage complet, texture sans bille), le même protocole de test va bientôt être appliqué, et l'on disposera alors de résultats similaires (mais qu'on peut raisonnablement espérer meilleurs).
Une séquence vidéo présente un message audio-visuel (2Mo), resynthétisé après analyse :