Version du 12/12/2001
Contributeurs : F. Elisei, M. Odisio et G. Bailly
Institut de la Communication Parlée
INPG, 46 avenue Félix Viallet, 38031 Grenoble Cedex 1
{elisei, odisio, bailly}@icp.inpg.fr
Le précédent délivrable («Analyse labiale par approche descendante», juillet 2000) détaillait la méthodologie de construction et de rendu de clones 3D vidéo-réalistes développée à l'ICP. Il introduisait aussi nos diverses pistes de recherche pour réaliser l'analyse de vidéos, c'est à dire trouver les paramètres (articulatoires) de codage de l'image du locuteur cloné, dans le mode labiophonie (en mode mono-locuteur, par approche descendante).
Ce nouveau délivrable fige une solution unique, définitive, au problème de l'analyse : il est fourni avec une implémentation logicielle de référence et un jeu de données à titre d'exemple. Pour aider à la réalisation matérielle prévue dans les autres sous-projets, quelques bornes sur la complexité du rendu des clones ont aussi été explicitées, ou artificiellement définies, tandis que les algorithmes de texturage étaient simplifiés. Enfin, l'interconnexion entre les terminaux que vise le projet TempoValse devant s'effectuer par un codage à la norme MPEG-4 (envoi de flux de FAP), on présentera un nouvel algorithme de conversion entre ces FAP et les paramètres articulatoires qui pilotent les clones.
On trouvera donc dans ce délivrable, en plus du package logiciel (Minnie, ses sources, un mode d'emploi et des données d'exemple) :
| - la description d'une plate-forme logicielle de référence, pour le rendu et l'animation des clones, ainsi que pour l'analyse labiale (mono-locuteur, par approche descendante) et à quoi elle correspond en terme d'algorithmes utilisés, | page 3 |
| - une explicitation de la complexité des clones (nombre de sommets et triangles, caractéristiques des textures...) utile à l'implémentation matérielle, | page 7 |
| - un mode de traduction entre les valeurs de codage FAP compatibles MPEG-4 et les paramètres articulatoires des clones. C'est le passage des FAP MPEG4 vers les valeurs articulatoires qui est délicat et a nécessité la création d'un nouvel algorithme, | page 13 |
| - la conclusion et les perspectives liées à l'état d'avancement actuel. | page 18 |
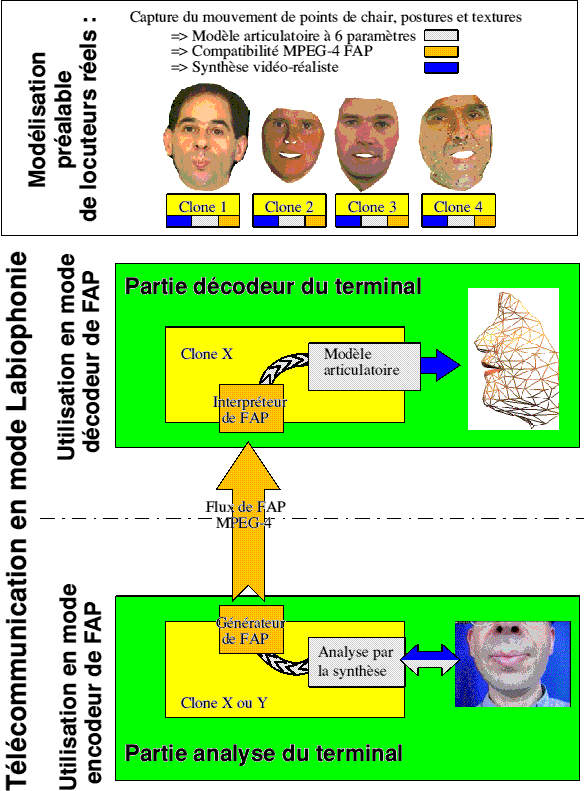
On ne retrouvera pas ici la méthodologie de création des clones, complètement décrite dans le précédent délivrable. Rappelons simplement qu'elle consiste à créer un clone personnalisé d'une personne réelle, en capturant les déplacements de points de son visage (peau, lèvres...) lors de son activité de parole. Celle-ci peut alors être représentée par un simple modèle linéaire à 6 paramètres. Il suffit à représenter de façon compacte et video-réaliste les apparences de ce visage parlant, et constitue aussi la donnée de base de l'algorithme d'analyse par la synthèse, capable de retrouver les paramètres articulatoires utiles pour représenter/coder une vidéo par son équivalent en mode labiophonie, comme le résume la figure qui suit.
Fig. 1 : Principe de l'utilisation en mode labiophonie
Cette partie du document présente la plate-forme logicielle qui a été produite pendant le projet. Celle-ci propose une mise en ›uvre minimale en langage C et avec la libraire graphique 3D Open GL. Elle permet le rendu et l'animation des clones réalistes, ainsi que leur utilisation pour l'analyse labiale (sans temps réel). Avec les données et algorithmes déjà présentés dans le précédent délivrable, ils permettent l'étude d'une implémentation matérielle, et notamment une éventuelle approximation par des opérations en 2D.
Courant octobre 2000, une première plate-forme logicielle (appelée Minim) était fournie aux partenaires du projet. Elle ne réalisait que la synthèse (rendu et animation) des clones vidéo-réalistes, et a depuis été intégrée dans le demonstrateur Impact de France Télécom. Pendant ce temps, la plate-forme Minim a évolué pour intégrer les aspects de l'analyse labiale (analyse par la synthèse) : utilisation d'un modèle probabiliste (teinte chair vs teinte lèvres) pour le calcul des images d'erreurs, et optimisation des paramètres articulatoires (algorithme du Simplexe). C'est cette nouvelle plate-forme, datée de mars 2001, compatible avec Minim et appelée Minnie, qui est présentée dans cette partie du document.

Rendu fil-de-fer Rendu
texturé Rendu avec superposition sur image
réelle
Fig 1.1 : Sorties graphiques obtenues avec la
plate-forme logicielle de synthèse et d'analyse
Les sources fournis permettent de recompiler l'application Minnie . Ils n'utilisent, en plus du C standard, que quelques unes des fonctionnalités d'Open GL. Si l'on fait abstraction des (nombreuses) commandes de configuration, il s'agit principalement de déclarer la caméra et de transférer les coordonnées (3D et texture) des points des triangles. On trouvera par exemple une documentation en ligne des fonctions GL sur :
http://www.dgp.toronto.edu/people/van/courses/opengl/opengl_index_alpha. html
Pour la recompilation, une librairie compatible Open GL sera nécessaire. On trouve sur ces systèmes :
Afin de pouvoir afficher directement leurs résultats, les programmes fournis utilisent quelques appels à la librairie GLUT. Cette petite librairie n'est généralement pas installée en standard mais est par exemple disponible (sources ou versions pré-compilées pour différents OS + fichiers .h) sur le site : http://reality.sgi.com/mjk/glut3/glut3.html
En plus des sources, l'implémentation de référence est fournie avec sa propre documentation (MINNIE.ps), quelques données de test et un jeu de scripts d'exemple ( _show_examples). Nous ne rappellerons ici que les parametres possibles lors de l'appel, pour faire le lien avec les structures et données présentées dans la partie II :
| -cam FILE | modèle de caméra | |
| -msh FILE | maillage | |
| Options | -mdl FILE | modèle d'animation (points articulés et points rigides) |
| du | -art FILE | séquence de paramètres articulatoires |
| Rendu | -back FILE | image en arrière-plan, potentiellement utilisée pour le tracking |
| -mov FILE | séquence de mouvements rigides | |
| -tex FILE | jeu de textures utilisé | |
| -pnm PREF | préfixe pour la sauvegarde des rendus | |
| -pts FILE | sauvegarde des points 3D du premier rendu | |
| Sorties | -pos FILE | sauvegarde des coordonnées de texture du premier rendu |
| -tpar PREF | préfixe pour la sauvegarde des séquences
(paramètres articulatoires et/ou mouvements rigides) issues de l'analyse | |
| -col FILE | modèle probabiliste discriminant peau/lèvres | |
| -trka | tracking des paramètres articulatoires | |
| -dtx | tracking avec détramage logiciel en X | |
| Tracking | -dty | tracking avec détramage logiciel en Y |
| -seq NUM | tracking d'une séquence où les noms des images sont
obtenus en incrémentant (jusqu'à NUM) les 4 derniers chiffres du nom de l'image en arrière-plan (-back) | |
| -neval NUM | tracking limité à NUM évaluations de la fonctionnelle d'erreur |
Nous ne présenterons pas ici les éléments relatifs au rendu : les algorithmes utilisés sont ceux décrits dans le précédent délivrable, même si Open GL oblige parfois à une implémentation moins optimale (3 passes de rendu par exemple) que celle qui est possible et souhaitable sur un terminal dédié.
Par contre, en ce qui concerne l'analyse, il convient de spécifier lequel des trois algorithmes introduits lors du précédent délivrable a finalement été retenu : il s'agit de l'analyse utilisant un traitement probabiliste chromatique de l'image caméra et du modèle texturé.
 |  |
Effectuer une analyse par la synthèse, c'est trouver pour les paramètres articulatoires un jeu de valeurs tel qu'une image donnée du locuteur soit approchée au mieux par le modèle de synthèse : chaque pixel synthétisé projeté depuis le modèle est comparé avec le pixel de l'image réelle (caméra) qu'il recouvre. L'erreur constituée par la somme des carrés des différences pixel-à-pixel renseigne sur un alignement global d'autant meilleur que l'erreur sera faible.
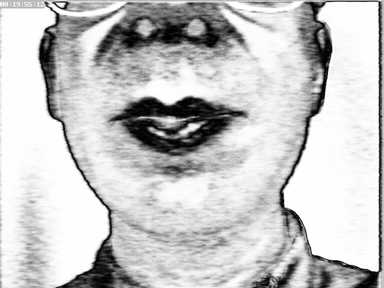
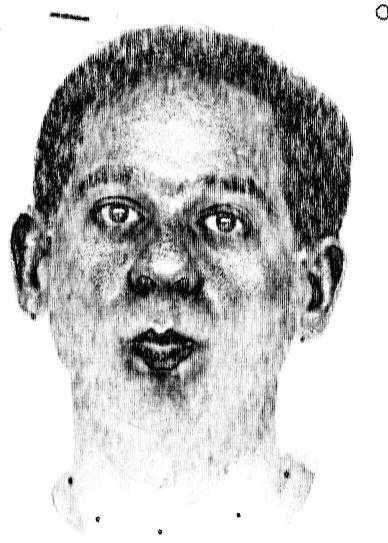
Dans le cadre de TempoValse, on se donne le clone du locuteur (apparence 3D, texture et animation). Sans maquillage, en situation de télécommunication, l'image synthétisée reste différente de la source caméra, à cause de l'éclairage (même en normalisant les images ou les zones traitées) ou de la pilosité faciale par exemple. Plutôt que d'exploiter directement les données brutes, RGB, on va renforcer des contrastes plus invariants : ceux entre les lèvres et la peau (figure I.2).
En pré-calcul, les textures du modèle ont subi le prétraitement chromatique présenté dans le précédent déliverable (repris page 9, équation (3)). Ce sont donc des textures en niveaux de gris (à gauche de la figure I.2), où la valeur de chaque pixel représente sa probabilité d'être un point des lèvres. En cours d'analyse, on fait subir à chaque image provenant de la caméra un traitement comparable, mais avec des paramètres adaptés aux conditions du moment (Cf. partie droite de la figure I.2). Ainsi, au lieu de mettre en correspondance des pixels RGB, le calcul de l'erreur pixel-à-pixel mesurera la corrélation des mesures de probabilité (d'être des points vermillon ou pas). Sans expliciter au pixel près leurs contours, cette méthode privilégie les zones des lèvres sans forcément cacher d'autres détails (grains de beauté par exemple) si le maillage de la synthèse couvre une zone suffisamment étendue.
L'optimisation est désormais réalisée par un algorithme de minimisation classique, celui du Simplexe, comme suggéré dans le rapport d'Eric Petit. Lorsque l'on cherche 6 paramètres articulatoires, ce sont 7 sommets (du Simplexe) qui vont converger autour d'un minimum local, qui se rèvèle en pratique un minimum global (grâce au casque micro-caméra, la recherche de l'articulation s'effectue sans gérer celle de l'alignement de la tête).
L'archive fournie inclut les images et paramètres résultats de diverses synthèses et analyses de séquence. La figure suivante ne reprend qu'une seule de ces images, superposant en fil-de-fer le résultat de l'analyse à une image de type micro-caméra.
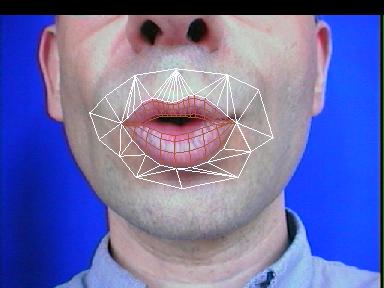
Fig. I.3 : Visualisation d'un résultat d'analyse
Ce chapitre a pour but de faciliter l'étude d'une implémentation matérielle, en bornant ou illustrant les tailles des données utilisées pour décrire le clone et l'environnement d'analyse. Pour ce faire, toutes les opérations mises en ›uvre lors du rendu d'un clone ou de l'analyse labiophonique (descendante, mono-locuteur) vont être explicitées avec quelques données quantitatives. En particulier, des contraintes fortes ont été instaurées sur les textures pour faciliter et accélérer les phases de rendu et d'analyse pour le terminal.
Au cours de l'avancement du projet, 4 locuteurs ont été modélisés : 1 locuteur français, une locutrice bilingue (français et anglais), 1 locuteur allemand et 1 locuteur arabe. L'application de la procédure de modélisation décrite dans le précédent délivrable a donc conduit à 4 clones, représentés sur la figure suivante, et dénommés par la suite PB, HL, MEH et MH.
 |
| Pour effectuer le rendu d'un clone, le terminal utilisera : | avec Minnie : |
| - un modèle des points mobiles. Piloté par un petit nombre de paramètres, le modèle articulatoire est un modèle linéaire, donc facile à évaluer. Il gère le déplacement 3D d'un certain nombre des points mobiles (visage ou lèvres) du clone. Le clone possède aussi un ensemble de points statiques. Avec des coordonnées 3D totalement figées, ils complètent la collection précédente pour décrire le reste du visage | -mdl |
| - un modèle géométrique. On spécifie la topologie, sous forme d'un réseau de triangles, qui permet de connecter tous les points 3D du visage. Selon qu'ils sont ou ne sont pas liés à des points mobiles, certains triangles se déformeront à la projection. En logiciel, cette différenciation n'est pas faite : la caméra et l'objet sont mobiles et traités le plus génériquement possible. | -msh |
| - un modèle de caméra. Il spécifie comment l'on transforme tous les points 3D en coordonnées écran. | -cam |
| - un modèle de rendu texturé. On part d'un nombre restreint de configurations articulatoires réelles, prises comme exemples, avec pour chacune : la texture ainsi que les positions 3D et les positions 2D de tous les points. Pour pouvoir mélanger ces postures clefs et créer un rendu de toute configuration, chacune est fournie avec un coefficient, précalculé, qui exprime son «potentiel d'influence». | -tex |
| Pour pouvoir effectuer aussi le travail d'analyse des images micro-caméra, il faudra en plus disposer : | avec Minnie : |
| - de vrais modèles de caméra et de position de l'objet. Il semble cette fois complètement indispensable de disposer d'une vraie transformation paramétrable, pour modéliser la direction de prise de vue de la caméra ou le positionnement relatif du sujet (variables d'une séance à l'autre...), mais aussi pour minimiser les déformations (non linéaires) de la micro-caméra. | -cam -mov |
| - de deux modèles couleur de la discrimination teinte chair/teinte lèvres. L'un s'applique aux textures et est donc connu en même temps qu'elles, l'autre est lié aux images micro-caméra et est donc susceptible de varier avec l'éclairage et le sujet. Parce qu'il s'applique pixel à pixel, ce traitement -- un changement d'espace couleur paramétré -- est susceptible de s'effectuer efficacement en matériel. | -col |
| - d'un sous-ensemble de l'objet. Les lèvres et le proche pourtour, plutôt que le modèle complet de visage, doivent être utilisés pour une analyse plus rapide. | -msh |
| - d'une fonctionnalité de différence (pixel à pixel) d'image, pour quantifier si la synthèse en niveaux de gris (probabilités) s'approche de l'image (rehaussée par le modèle couleur) de la micro-caméra. Dans l'implémentation logicielle actuelle, la comparaison est très coûteuse et se fait après la synthèse. On imagine qu'une accélération matérielle peut envisager d'autres pistes plus efficaces : composition directe des triangles synthétisés en différence sur l'image de fond, accumulation à la volée du résultat... | en dur dans le code |
L'origine du repère 3D du monde (celui où sont
exprimés tous les points avant projection à
l'écran) se situe en bas des incisives supérieures du
modèle. Toutes les coordonnées de points 3D sont
exprimées en centimètres par rapport à cette
origine, avec l'axe des X qui se confond avec l'axe gauche/droite du
visage, un axe des Y qui est plutôt orienté haut/bas, et
les Z qui codent plutôt la profondeur. En utilisant pour la
projection une simple remise à l'échelle des couples ![]() des points
3D du modèle on aura donc bien une vue de face (aux
éventuels problèmes de visibilité
avant/arrière près).
des points
3D du modèle on aura donc bien une vue de face (aux
éventuels problèmes de visibilité
avant/arrière près).
À chaque point mobile sont associés une position au repos
et autant de vecteurs (3D) de déplacements qu'il y a de
paramètres articulatoires. Ainsi la position du point ![]() pour des
valeurs articulatoires
pour des
valeurs articulatoires ![]() se calculera par la combinaison linéaire
suivante :
se calculera par la combinaison linéaire
suivante :
![]()
![]()
Avec ![]() points statiques et
points statiques et ![]() points animés, il y a donc
points animés, il y a donc ![]() vecteurs
à mémoriser.
vecteurs
à mémoriser.
Les 30 premiers points mobiles sont toujours des points de lèvres, et leur maillage (pas leur position !) reste toujours le même, quel que soit le locuteur.
Optimisation : Les points statiques sont assez nombreux dans le cas 3D ; on pourrait envisager de réduire leur nombre pour les seules vues de face, et ce d'autant plus qu'on s'éloigne des zones animées. Mais on aurait alors à texturer des triangles plus grands. Quel serait le bon compromis pour le matériel ?
Le modèle de projection perspectif s'exprime en coordonnées homogènes sous la forme :

C'est à dire que, par exemple, l'abscisse de la projection
à l'écran de ![]() vaut :
vaut :
![]()
En l'absence de Z-buffer, les troisièmes lignes de la matrice et du résultat peuvent être ignorées. Pour une simple projection euclidienne, on n'utiliserait bien sûr plus que les deux premières lignes.
Dans le cas d'OpenGL, les coordonnées écran sont
normalisées : quelle que soit sa taille, le centre de
l'écran est représenté par ![]() et les
coins sont de la forme
et les
coins sont de la forme ![]() . Les matrices fournies pour les jeux d'exemples
respectent cette règle.
. Les matrices fournies pour les jeux d'exemples
respectent cette règle.
Optimisation : Un modèle trop simple de caméra interdira l'utilisation du terminal pour l'analyse ! Il faut pouvoir déplacer la tête (au niveau du modèle de caméra ou par une autre matrice de rotation/translation qui s'applique aux objets), à cause du positionnement ou du réglage du casque, variables d'une séance sur l'autre. Il faut aussi pouvoir compenser les déformations (la composante perspective au moins) dues à la focale courte de la micro-caméra.
Chaque texture est fournie avec la position 2D associée des points du modèle (dans le même ordre : les 30 points de lèvres, puis les autres points mobiles puis les points statiques). S'il n'y avait qu'une seule texture, cela suffirait à spécifier le rendu : chaque triangle à afficher aurait son antécédent dans l'image de référence. Mais on a déjà montré qu'il fallait plusieurs textures (on en utilise typiquement 3) pour avoir un rendu plus réaliste (apparition du pli naso-génien, meilleure définition des lèvres en protrusion...).
Avec plusieurs textures, il faut spécifier comment chacun des (trois) antécédents texturés influence le rendu de chaque triangle d'une posture cible. On ne peut pas se permettre de choisir une seule texture (la plus proche) à un moment donné : cela produirait des discontinuités (temporelles) lors du rendu. Au contraire, on applique à tout moment un mélange des différentes textures, dans des proportions qui varient continûment dans le temps. C'est le rôle du jeu de positions 3D et du coefficient de pondération associés à chaque posture de référence que de déterminer en dynamique le dosage du mélange des pixels de texture :
![]()
![]()
où l'ensemble de points ![]() représente la posture à
synthétiser (produite par l'équation (1) à un
moment donné d'après les paramètres
articulatoires) et où chaque
représente la posture à
synthétiser (produite par l'équation (1) à un
moment donné d'après les paramètres
articulatoires) et où chaque ![]() est le jeu (fixe pour un modèle
donné) des points de la
est le jeu (fixe pour un modèle
donné) des points de la ![]() ème position de
référence, associée au
ème position de
référence, associée au ![]() .
.
Optimisation : On peut envisager de calculer la distance entre deux configurations autrement que par la somme des distances entre tous les points. Calculer la distance entre les paramètres articulatoires ne semble a priori pas très pertinent (les articulateurs n'ont pas une influence homogène : en protrusion, la peau est plus déformée que par les simples mouvements de mâchoire). Un sous-ensemble de points serait peut-être suffisant si l'implémentation matérielle de l'équation 2 pose problème ?
Optimisation : Comme les coefficients ![]() s'appliquent à tous les pixels de la texture, il est possible de
mélanger efficacement (pixel à pixel, en balayage
raster) les images pour ne faire qu'un seul rendu texturé
si et seulement si les coordonnées 2D sont identiques pour
tous les visèmes. Cette optimisation -- qui demande à
remplacer des textures provenant de prises de vues réelles par
des textures ayant subies un pré-traitement -- sera
présentée au II.2
s'appliquent à tous les pixels de la texture, il est possible de
mélanger efficacement (pixel à pixel, en balayage
raster) les images pour ne faire qu'un seul rendu texturé
si et seulement si les coordonnées 2D sont identiques pour
tous les visèmes. Cette optimisation -- qui demande à
remplacer des textures provenant de prises de vues réelles par
des textures ayant subies un pré-traitement -- sera
présentée au II.2
Un pixel RGB est remplacé par une probabilité ![]() ,
calculée comme suit :
,
calculée comme suit :
![]()
![]()
où ![]() est le vecteur discriminant,
est le vecteur discriminant, ![]() la moyenne et
la moyenne et ![]() l'écart type fournis par la procédure d'apprentissage
déjà présentée dans le
précédent délivrable.
l'écart type fournis par la procédure d'apprentissage
déjà présentée dans le
précédent délivrable.
La tête observée par la caméra peut se retrouver placée différement d'une scéance à l'autre. On peut compenser ce mouvement (rotation et translation) directement dans la matrice caméra. Mathématiquement et pour des raisons pratiques (optimisation plus simple de coefficients non-liés), on a intérêt à séparer les problèmes et utiliser une matrice de roto-translation :
![]()
Celle-ci peut être multipliée (à droite) avec la
matrice caméra. On peut aussi utiliser directement ![]() et
et ![]() pour
transformer les points 3D (fixes et animés) avant chaque
projection caméra.
pour
transformer les points 3D (fixes et animés) avant chaque
projection caméra.
Suite à la création des 4 clones déjà présentés, on peut raisonnablement fixer les bornes suivantes :
| Objet | Contrainte |
| points mobiles | 250 |
| points fixes | 200 |
| triangles pour la synthèse | 700 |
| triangles pour l'analyse | 50 |
| nombre de textures | 3 |
| taille des textures photo-réalistes | 512x512, couleur |
Afin de faciliter l'application des textures multiples (opération réalisée en plusieurs passes en OpenGL) et minimiser les opérations matérielles (interpolation des coordonnées de texture lors de l'affichage d'un triangle de texture, accès mémoires, problèmes de précision lors de la composition des pixels...), un nouveau précalcul a été introduit lors de la capture des clones. Il consiste à re-projeter les textures originales (typiquement 3) sur un même maillage (commun aux trois postures donc). Ce faisant, on bénéficie dès lors d'un paramétrage identique pour les 3 couches de texture. Cela permet par exemple de mélanger pixel à pixel (algorithme raster efficace) les images de texture, pour les combiner en une seule (texture dynamique qui dépend/varie avec les coefficients de mélange). Celle-ci peut alors être appliquée/projetée en une seule passe pour texturer le clone.
Comme l'illustre la figure suivante, on peut aussi lors de cette étape de création des textures, et pour chaque posture articulatoire, en profiter pour mélanger plusieurs vues (plutôt qu'utiliser une seule vue de face). On obtient des textures dites «cylindriques» qui détaillent le visage sans privilégier la vue de face.
En appliquant ces deux pré-traitements, on créera un jeu de 3 textures cylindriques, avec un paramètrage commun et une bonne définition.
 |

|
|
La formule présentée dans le précédent déliverable reste valide, et doit toujours être employée pour effectuer le pré-traitement de chaque image provenant de la caméra (Cf. équation 3). Il était par contre souhaitable de simplifier son application (produit scalaire et/ou indexation d'une table d'exponentielle pour chaque pixel synthétisé) coûteuse et répétée à chaque itération de l'algorithme d'analyse par la synthèse. L'approximation simplificatrice qui a été testée et retenue consiste à appliquer une fois pour toutes le traitement probabiliste (rehaussement du contraste lèvres/peau) sur chacune des textures. Pour la synthèse destinée à l'analyse, on combine ensuite ces textures en niveaux de gris linéairement (pixel à pixel, comme présenté à la section II.2, avec les pondérations données par l'équation (2)) exactement comme pour la phase de rendu avec textures réalistes.
MPEG-4 et ses Facial Animation Parameters normalisent un codage de l'animation de visages 3D, mais sans suggérer aucun algorithme pour le problème délicat de leur utilisation (interprétation) du coté du récepteur : comment peut-on, à partir de l'échantillonnage de quelques déplacements à la surface d'un visage, recréer des mouvements fins et naturels pour tous les points d'un visage 3D ? Ce chapitre propose de réaliser cette tâche à l'aide de modèles linéaires, les clones articulatoires précédemment construits. Sans sortir de la norme MPEG4, un tel modèle gagne à être intégré à un décodeur pour interpréter et extrapoler de façon robuste les valeurs d'animation (FAP) reçues, et obtenir un visage à l'animation non-caricaturale. En plus de cet algorithme d'interprétation des FAP, on détaille aussi une évaluation quantitative de la dégradation du codage/décodage d'un visage parlant, mettant en avant les gains en robustesse et en débit.
Le standard MPEG-4 permet un codage efficace de scènes audiovisuelles par une représentation adaptée des objets y apparaissant. On peut notamment spécifier un visage 3D, aussi bien dans son apparence que pour son animation, par exemple synchronisée avec un synthétiseur vocal opérant d'après des données textuelles. La norme MPEG-4 prévoit, pour les implémentations de haut-niveau, de pouvoir adapter le modèle présent dans le terminal selon diverses caractéristiques envoyées par le serveur :
Pour le profil minimal simple face, ces extensions (gestion des
FDP, Facial Definition Parameters) ne sont pas
exigées. On reste donc dans la norme en ne les
implémentant pas immédiatement, et en
s'intéressant d'abord aux problèmes liés à
l'animation réaliste pour la labiophonie. En effet, les visages
3D compatibles MPEG-4 doivent être animés par un flux de
paramètres, les FAP (Facial Animation Parameters),
qui sont très différents des paramètres
articulatoires qui émergent lors de la création des
clones. Il va donc falloir effectuer la conversion FAP ![]() articulatoire dans les deux sens :
articulatoire dans les deux sens :

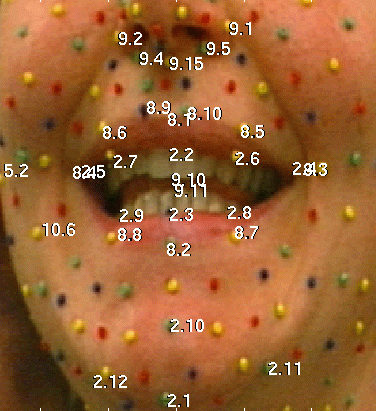
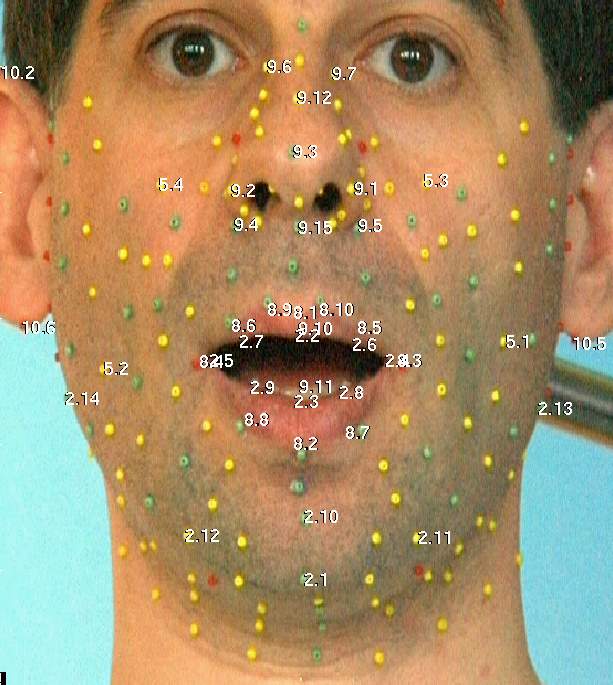
Fig. III.1: Les 84 points de calibration de MPEG-4, où s'ancrent 66 FAP pour coder l'animation de bas niveau
MPEG-4 définit pour les visages 84 points de calibration (cf. figure III.1). Chacun des 66 FAP de bas niveau encode le déplacement suivant une seule direction (soit X, soit Y, soit Z, soit une rotation autour d'un seul de ces axes) de l'un des 84 points de calibration. Par exemple, le FAP 3 (Open Jaw) contrôle le déplacement en Y du point 2.1, dont le X et le Z sont respectivement attachés au FAP 15 (Shift Jaw) et au FAP 14 (Thrust Jaw). En fait, seul un très petit nombre des 84 points ont leurs 3 coordonnées directement attachées à 3 FAP : la plupart des points du visage (ou de leurs coordonnées) ne sont animés qu'implicitement, en étant influencés à distance par l'ensemble des FAP. C'est par exemple le cas du point 5.1 (centre de la joue gauche) qui n'est attaché qu'au seul FAP 39, pour contrôler son X. Son Y et son Z ne sont pas fixes (la bosse de la joue s'animera aussi là) mais ils ne sont directement attachés à aucun FAP : c'est aux décodeurs d'extrapoler «leur» déplacement 3D naturel. D'autres points, comme les très mobiles 8.9 et 8.10 de l'arc supérieur des lèvres, devront être entièrement extrapolés.
Pour faciliter le contrôle de clones ou d'avatars aux géométries différentes par les même valeurs de FAP, cellesci représentent en fait des proportions, exprimées relativement à des distances mesurées sur les visages au repos (espacement des yeux, largeur de la bouche...).
La génération de FAP est aisée si l'on sait faire de la synthèse (après analyse par exemple) de clones, comme nous le rapellerons au III.3.1 . Voyons maintenant l'aspect qui reste délicat : l'animation d'un visage par un jeu de FAP.
Le standard permet les situations où le décodeur ne reçoit de valeurs que pour un sous-ensemble des 66 FAP. Il lui incombe alors d'inférer les valeurs absentes pour animer des clones de façon réaliste.
Pour être compatible, un décodeur se doit aussi de fournir son propre modèle générique, propriétaire. Utilisé par défaut, il permet les communications aux plus bas débits puisque seuls les FAP ont besoin d'être transmis (sans clone à télécharger). En pratique, pour que le maillage du visage ne présente pas un aspect anguleux, les modèles de visage comportent généralement bien plus que les 84 points animés suggérés par la figure 1.
La difficulté est donc de déplacer tous les points du visage d'après un petit sous-ensemble de leurs coordonnées que des valeurs de FAP spécifient. La norme ne spécifie pas comment doit s'exercer cette influence. Pour un résultat réaliste, le décodeur devrait posséder un minimum de connaissances, une certaine expertise de comment s'anime un visage.
La plupart des décodeurs se contentent de simples lois de propagation ou de quelques règles empiriques pour propager les déplacements. D'autres obtiennent des résultats plus réalistes à l'aide d'un modèle bio-mécanique, dur à construire et à simuler de façon stable, mais cette méthode semble trop coûteuse pour un décodeur temps-réel. L'approche réaliste et rapide que nous proposons utilise le modèle articulatoire de nos clones : compact, linéaire, celui-ci a effectivement «appris» les postures atteignables d'un locuteur réel.
Par le paradigme proposé pour la capture de l'activité de parole, on sait obtenir un modèle 3D d'animation avec un contrôle linéaire simple (6 paramètres), sans compromettre son réalisme. Ce modèle, avec beaucoup moins que 66 paramètres, contrôle bien plus de 84 points mobiles, dont certains sont bien sûr en correspondance directe avec les points caractéristiques MPEG-4, comme sur la figure III.2. Le terminal doit aussi connaître la position neutre associée à ce clone. Comme la procédure de construction du modèle produit des tailles réelles (en centimètres), il a aussi accès aux unités/étalons dans lesquelles sont exprimés les FAP.
 |  |
Il n'y a aucune difficulté à passer des paramètres articulatoires aux positions 3D puis aux valeurs des FAP : pour chaque point du modèle qui est associé à un ou plusieurs FAP, il suffit de diviser par l'unité ad hoc le déplacement par rapport à la position neutre. Ces valeurs de FAP sont prêtes à être transmises (quantifier, coder...) à un autre poste MPEG-4.
Voyons justement comment réaliser l'opération inverse (passer des FAP aux valeurs articulatoires), et comment le modèle linéaire d'un clone (possiblement différent de celui utilisé à l'analyse) peut servir à interpréter et régulariser un jeu de valeurs de FAP.
Après le décodage du flux de FAP, le décodeur
dispose d'un ensemble de valeurs pour certains FAP de bas-niveau. On va
chercher quel vecteur de paramètres articulatoires ![]() les
prédirait le plus précisément avec
l'équation (1). Les FAP connus affectent expressément un
sous-ensemble
les
prédirait le plus précisément avec
l'équation (1). Les FAP connus affectent expressément un
sous-ensemble ![]() des coordonnées du modèle. Le FAP 3 par exemple
(Open Jaw) ne fixe que le Z d'un point du menton (2.1), et
fournit une seule équation.
des coordonnées du modèle. Le FAP 3 par exemple
(Open Jaw) ne fixe que le Z d'un point du menton (2.1), et
fournit une seule équation.
On isole donc le sous-modèle contraint par ![]() en ne
conservant de l'équation (1) que les lignes
concernées : à
en ne
conservant de l'équation (1) que les lignes
concernées : à ![]() et
et ![]() se substituent donc
se substituent donc ![]() et
et ![]() . La
différence
. La
différence ![]() représente alors l'erreur
géométrique (par exemple en millimètres) de
réalisation des FAP transmis. Comme le modèle est
linéaire, la réalisation optimale de ce critère au
sens des moindres carrés correspond à la
résolution du système linéaire simple :
représente alors l'erreur
géométrique (par exemple en millimètres) de
réalisation des FAP transmis. Comme le modèle est
linéaire, la réalisation optimale de ce critère au
sens des moindres carrés correspond à la
résolution du système linéaire simple :
![]()
![]()
![]()
Quel que soit le nombre de FAP dont la valeur est connue (au moins 6,
un peu plus pour des raisons de stabilité), le système
à résoudre (ou la matrice à inverser) est de
taille ![]() (soit
(soit ![]() pour la parole). Les valeurs de
pour la parole). Les valeurs de ![]() (et de ses composées...) ne
dépendent que du sous-ensemble de FAP (pas de leurs valeurs,
comme c'est le cas pour
(et de ses composées...) ne
dépendent que du sous-ensemble de FAP (pas de leurs valeurs,
comme c'est le cas pour ![]() ), de sorte qu'un système de cache logiciel
de la pseudo-inverse, entre crochets dans l'équation (4),
est aussi envisageable.
), de sorte qu'un système de cache logiciel
de la pseudo-inverse, entre crochets dans l'équation (4),
est aussi envisageable.
Le vecteur ![]() ainsi obtenu contient des valeurs articulatoires
ainsi obtenu contient des valeurs articulatoires ![]() qu'on peut
injecter dans l'équation (1) pour obtenir la position de tous
les points animés du modèle, et donc extrapoler la valeur
des FAP non transmis.
qu'on peut
injecter dans l'équation (1) pour obtenir la position de tous
les points animés du modèle, et donc extrapoler la valeur
des FAP non transmis.
Les vidéos produites montrent des séquences de FAP de parole où sont juxtaposées la vidéo originale, la séquence reconstruite (avec le modèle «exact» du locuteur), et la séquence de FAP interprétée par les autres clones.
 |
 |
La piste sonore semble bien cohérente avec les mouvements reconstruits : tous les clones ont des mouvements synergiques (arrondissement des lèvres, abaissement de la mâchoire...) et les buts géométriques (fermeture des lèvres pour les [p] et les [b] par exemple) sont préservés.
On note aussi que les idiosyncrasies des locuteurs persistent naturellement : ainsi, sur la figure III.3, les clones diffèrent par le placement relatif de leurs lèvres. En préservant ces détails, en cohérence avec leurs anatomies, le modèle contribue au réalisme du résultat.
Trouver des paradigmes d'évaluation dans le cadre des codages hybrides de MPEG-4 SNHC peut s'avérer très délicat : l'objet synthétique reconstruit est généralement censé restituer la sémantique du message à transmettre, sans autre fidélité «calculable» au signal original.
Pour dépasser l'évaluation subjective de la qualité des vidéos proposées, on se place dans une configuration très particulière : la transmission d'une séquence «parole» de 36 secondes, résultat d'une analyse de vidéo avec le même modèle que celui présent dans le décodeur. Ainsi, on pourra calculer la dégradation des FAP finalement utilisés, à l'aide du PSNR (rapport signal sur bruit pic-à-pic) de FAP.
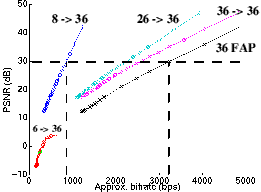
Fig. III.4: Liens entre débits et qualités, avec (o) ou sans (x) régularisation par un modèle du locuteur
Chaque trame de la séquence analysée (parole «pure») était représentée par 36 FAP. Les divers protocoles appliqués pour aboutir aux courbes de la figure III.4 sont :
- compression du flux des 36 FAP avec la méthode à faible délai prévue par la norme : une quantification plus ou moins forte de la différence temporelle, suivie d'un codage arithmétique. La fidélité baisse en même temps que le débit, c'est la courbe de référence, avec les croix noires, n'utilisant pas de modèle caché.
- régularisation selon l'équation (4) des 36 FAP (compressés) reçus par trame, en utilisant le modèle de l'analyse. Pour le débit exact de la courbe de référence, on gagne 7dB : les corrélations du système permettent de retrouver une partie des décimales perdues par la quantification.
- transmission de sous-ensembles réduits des 36 FAP (resp. 26, 8 et 6), pour des débits réduits. Des valeurs pour les 36 FAP sont retrouvées/extrapolées grâce au modèle articulatoire du décodeur.
Dans ces conditions privilégiées de régularisation, un rapport signal/bruit de 30 dB s'obtient avec 8 FAP (3, 14, 16, 17 et 51 à 54) pour moins de 1kbps. C'est moins du quart de l'approche classique (quantification des 36 FAP). Le modèle caché agit donc aussi comme un filtre.
Plus généralement, dans un décodeur MPEG-4 FACE, le modèle générique est bien sûr différent de celui du locuteur d'origine. Sur les images et vidéos produites, il semble bien que ce pouvoir de régularisation des valeurs de FAP persiste, au moins pour les valeurs de quantification utilisables en pratique.
Dans un cadre où un filtre temporel trop simple masquerait des évènements cruciaux (fermeture rapide de la bouche par exemple), le principe d'extrapolation/régularisation de FAP proposé ici agit en fait comme un filtre spatial. Il faudrait évaluer, à un niveau plus abstrait que celui du signal, si cela se fait de façon «réaliste».
Le paradigme d'évaluation de l'intelligibilité de la parole audio-visuelle pourrait être employé : on sait combien la compréhension de locuteurs humains chute lorsque la piste son d'un visage parlant est de plus en plus bruitée. Il faudrait effectuer de telles mesures avec des clones reconstruits, et les comparer avec celles des vidéos originales, ou d'autres décodeurs MPEG-4/FACE.
Pour un décodeur MPEG-4/FACE, nous avons présenté l'utilisation d'un modèle linéaire, «caché» afin de rester compatible avec le standard et tous ses profils. Une arithmétique simple, compatible avec le temps-réel, permet alors de régulariser et d'interpréter les flux de FAP reçus pour les rejouer sur n'importe quel modèle (propriétaire, ou transmis par le serveur). Cette approche permet de le rendre plus robuste au bruit de compression (ou d'abaisser le débit requis), voire de régulariser l'éventuel bruit (spatial) de FAP envoyés par le serveur.
Dans le cadre de TempoValse, on dispose donc des indispensables passerelles entre les clones vidéo-réalistes qui se pilotent «en interne» à l'aide de paramètres articulatoires qui leur sont propres, et un interfaçage pour le dialogue entre terminaux, standardisé suivant la norme MPEG-4 et ses FAP. On est donc bien dans la situation présentée en page 2 sur la figure 1.
À l'aide de clones, modèles précis de l'apparence et de l'articulation de locuteurs, l'approche proposée résoud le problème de l'analyse (descendante, mono-locuteur et sans temps réel en logiciel) de séquences vidéos de type «parole». On peut alors convertir ces vidéos en flux de FAP, au sens strict de la norme MPEG-4, et garantissant l'inter-opérabilité entre terminaux. Toujours dans le cadre MPEG-4, on propose un traducteur/décodeur de FAP qui résoud le problème délicat de la réception, quelle que soit la provenance du flux de FAP, dans le cadre de la labiophonie.
La prochaine étape consiste en l'évaluation, pour des utilisateurs réels, de ces clones. L'intelligibilité et la charge cognitive nous renseigneront sur l'acceptabilité et le réalisme des résultats en situation de parole (comprendre le message audio-visuel, dans un environnement bruité par exemple).
Avec l'apparition de briques matérielles accélérées et dédiées à la synthèse et l'analyse, le temps réel va peut-être pouvoir être réalisé et expérimenté plus tôt qu'anticipé lors du démarrage de ce projet. La disponibilité des clones déjà construits va peut être aussi permettre d'évaluer la qualité de la synthèse transposée sur un avatar, ou le tracking multi-locuteur, dans un domaine où quelques algorithmes empiriques existent mais sont très durs à évaluer, et donc à améliorer.
