 |  |
Version du 15/11/2002
Contributeurs : F. Elisei, M. Odisio
Institut de la Communication Parlée
INPG, 46 avenue Félix Viallet, 38031 Grenoble Cedex 1
{elisei,odisio}@icp.inpg.fr
Deux délivrables antérieurs (SP2, T2 & T3, juillet 2000 et décembre 2001) ont détaillé une méthodologie et des algorithmes qui permettent la réalisation de la labiophonie (en mode mono-locuteur, par approche descendante avec un modèle a priori). L'analyse de vidéos, afin d'extraire de chaque image du locuteur cloné les paramètres (articulatoires) qui le coderont dans son activité de parole est réalisée à l'aide du paradigme d'analyse par la synthèse : dans cette tâche d'optimisation, on cherche les valeurs de paramètres articulatoires qui vont minimiser l'erreur de re-synthèse (approcher au maximum l'image originale, où le contraste peau/lèvres aura été rehaussé par un pré-traitement couleur). La plate-forme logicielle de référence Minnie, qui a été fournie avec le délivrable T3, implémente exactement cet algorithme d'analyse par la synthèse. L'intérêt et l'adéquation pratiques ont déjà été illustrés par la production, avec une qualité subjective satisfaisante, de nombreuses vidéos et flux MPEG-4 (FAP codant l'animation de visages) tout au long du projet.
Ce nouveau délivrable propose des évaluations plus fines, et notamment quantitatives, de la précision ainsi que de la vitesse de convergence de l'algorithme et de la procédure d'optimisation implantés dans Minnie. On a pour cela enregistré puis utilisé quelques corpus de tests particuliers, pour lesquels on peut analyser soit l'erreur résiduelle de re-synthèse, soit la distance aux paramètres articulatoires attendus. Ces images pour lesquelles les paramètres articulatoires sont connus à la phase de construction du clone, ainsi que des séquences vidéos avec marqueurs ayant été étiquetées manuellement par un expert, seront présentées dans ce document, ainsi que l'analyse des résultats qui ont déjà été obtenus.
La suite du document est organisée comme suit :
| I | Principes et écueils d'un codage labiophonique | page 3 |
| II | Création et présentation des corpus de tests | page 5 |
| III | Évaluations qualitatives et quantitatives | page 9 |
| IV | Conclusion des évaluations | page 15 |
Cette partie du document rappelle succinctement quelques étapes du principe d'optimisation retenu et implanté dans la plate-forme logicielle Minnie (analyse par la synthèse, calcul d'erreur entre images réelles et synthétiques, optimisation par l'algorithme du Simplexe). On pourra alors expliquer pourquoi la labiophonie (comme n'importe quel paradigme de codage hybride/basé objet) exige que l'on se pose la question de l'évaluation des paramètres d'animation obtenus lors de l'inversion. Cela nous amènera à choisir et générer des corpus de test adaptés à une tâche d'évaluation.
Dans le mode de communication par Labiophonie, le locuteur filmé par la caméra sera représenté à distance par un modèle 3D, animé pour représenter son activité de parole. En plus de la brique de synthèse vidéo-réaliste, cela nécessite de savoir retrouver, pour chaque image du locuteur, les paramètres de contrôle correspondants pour son clone. L'algorithme qui a été retenu pour TempoValse, et qui utilise le paradigme de l'analyse par la synthèse a déjà été présenté en détails lors du délivrable SP2, Tâches 2 et 3. Les paragraphes qui suivent résument simplement les points qui sont d'importance pour la tâche d'évaluation que décrit ce délivrable.
Dès lors qu'on possède un modèle de synthèse d'un objet observable, on peut envisager de représenter (pour des besoins de codage et/ou de compression) celui-ci par son approximation synthétique. C'est le principe du codage basé objet, et la labiophonie en est une application : des modèles de visages 3D (clones ou avatars, selon que l'on est représenté fidèlement ou non) se substitueront aux flux vidéos des visages parlants, grâce à un flux des paramètres de contrôle de leur animation. Rappelons que les clones 3D que l'on a construits pour TempoValse sont tous contrôlés par :
Quels sont, à un moment donné, les paramètres qui modélisent le plus fidèlement l'image du locuteur qui parle face à la caméra ? Cette question difficile, récurrente à tous les codages basés objets, est celle de l'inversion des paramètres d'après l'image. Une telle opération, qui est l'inverse de la synthèse, peut être envisagée par le biais de l'analyse par la synthèse.
Le locuteur est donc filmé par une caméra (ou plus), qui a été calibrée (de sorte qu'un modèle de caméra permette la re-projection précise des synthèses dans l'espace de l'image).
Nous supposons que la synthèse est suffisamment vidéo-réaliste : déterminer le jeu de paramètres optimal revient à maximiser la similarité entre l'image réelle et l'image de synthèse. À chaque itération, la distance entre la posture articulatoire et l'image est assimilée à la différence entre l'image analysée Ia et la projection Is (p) du clone (on ne modélise pas l'arrière-plan), synthétisé avec le jeu courant des paramètres p. Pour réduire la dépendance aux conditions expérimentales et plus particulièrement aux conditions d'illumination, un pré-traitement des images est généralement appliqué : la figure III.1 illustre l'utilisation d'un modèle probabiliste de teinte qui amplifie le contraste peau-lèvres.
| |
La fonction d'erreur générique est ainsi définie comme :
![]()
![]()
où N est le nombre de pixels (u,v) synthétiques générés par le modèle dans Is (p). Les fonctions fx () représentent l'application des pré-traitements (potentiellement différents sur les images à analyser et les images de synthèse).
L'algorithme de Nelder-Mead du simplexe est utilisé pour déterminer itérativement les paramètres qui minimisent e. Cet algorithme est basé sur l'évaluation de la fonctionnelle aux sommets du simplexe, sans calcul de dérivées, ce qui permet d'explorer localement et à moindre coût la topologie de e.
D'autres méthodes, comme l'algorithme de Levenberg-Marquardt ou plusieurs techniques de recherche directe, ont été testées, mais elles ont donné des résultats de qualité inférieure tout en requérant un plus grand nombre d'évaluation de e.
On va voir que de nombreux facteurs influencent les valeurs de paramètres qu'on peut espérer retrouver lors de l'inversion, parfois indépendamment de tout choix algorithmique. C'est ce constat, général, qu'un codage basé objet «parfait» ne peut généralement pas être atteint, qu'une erreur de codage systématique existe, qui nous a bien sûr conduit à chercher à évaluer la qualité du codage qu'on obtient, dans la pratique, avec l'algorithme (une procédure de calcul qui construit un résultat en un temps fini) proposé pour TempoValse et la labiophonie par approche descendante.
Le modèle articulatoire permet un codage très compact (quasi sémantique) de l'apparence visuelle de l'activité de parole du locuteur. Avec 6 paramètres, on ne représentera pas toutes les postures possibles : des grimaces ou des expressions appuyées par exemple, seront filtrées par le modèle articulatoire qui ne sait pas les coder.
La synthèse ne reproduit pas non plus toutes les apparences visuelles possibles (barbes plus ou moins bien rasées par exemple). Même si le but du pré-traitement des images qui est utilisé lors de l'analyse est de s'abstraire autant que possible de ces différences (intensité et teintes de l'éclairage par exemple), elles auront probablement une influence sur le résultat de l'inversion, qu'on peut comparer à un bruit de codage. L'utilisation de textures, qui introduisent une discrétisation spatiale et divers artefacts lors du rendu graphique, fait aussi partis des facteurs susceptibles de bruiter l'inversion par analyse.
En résumé, tout algorithme d'inversion (y compris l'analyse par la synthèse) se comportera au mieux comme la projection du phénomène observé sur un espace de petite dimension : celui qui est modélisé et synthétisable. Il sera donc, au moins dans un premier temps, intéressant de s'intéresser à l'analyse d'images dont on sait qu'elles peuvent être générées par synthèse, puis de se rapprocher de conditions plus proches du réel, mais pour lesquelles on a une idée a priori des paramètres qu'on espère obtenir.
La synthèse, puis le calcul de l'erreur avec l'image caméra, permettent d'évaluer différentes hypothèses quant aux valeurs possibles des paramètres articulatoires, mais l'espace des paramètres ne peut pas être exploré complètement. À défaut, on doit compter sur un algorithme d'optimisation pour trouver en un temps fini un jeu de paramètres qui minimise autant que possible l'erreur de re-synthèse. Il faut faire appel à des processus itératifs, où la boucle synthèse/génération de nouveaux paramètres sera répétée plusieurs fois dans l'espoir de converger vers le minimum absolu ou au moins d'approcher un résultat acceptable.
Pour le choix d'un algorithme plutôt qu'un autre, ce qui influencera bien sûr la vitesse et la pertinence du résultat terminal, il faudra bien sûr s'intéresser à l'espace des erreurs : on sait que selon les cas (fonctions d'erreur continues, dérivables ou contractantes par exemple, mais aussi présence ou non de minimum locaux), certaines classes d'algorithmes seront optimales ou au contraire de mauvaises candidates. À défaut d'un résultat purement formel, une étude pratique avec un corpus adapté permettra plus sûrement de valider un choix acceptable.
Cette partie du document présente les corpus de test qui ont été créés. Ils seront notamment utilisés pour évaluer quantitativement les résultats de codage des algorithmes de Minnie et mesurent donc un certain critère objectif de qualité de l'application de labiophonie.
Dans le cas général du codage par objet, il est normal que l'image de re-synthèse soit différente de l'image à analyser : plus que le signal original, c'est une approximation de sa sémantique (idéalement, la part que le modèle a priori sait représenter de façon pertinente) qui sera transmise. En labiophonie, les pixels de la visiophonie ne sont pas transmis, pas plus que la luminosité du lieu où se trouve le locuteur réel : les 6 paramètres issus de l'analyse ne pourront générer qu'un faible sous-ensemble de toutes les combinaisons visuelles possibles des dizaines de milliers de pixels d'une image (dont toutes ne sont pas des visages). C'est bien évidement cette fidélité partielle du codage basé objet qui permet des taux de compression très élevés (6 paramètres par image pour la labiophonie, avant l'encapsulation au format MPEG-4) et on ne la remettra donc pas en cause.
Dans la tâche de télécommunication, il importe que le message re-synthétisé reste fidèle à celui articulé par le locuteur réel. Les évaluations subjectives classiques, ou des vérifications qualitatives de l'accord avec la phonétique articulatoire, mesurent quelque chose d'assez différent : un bon score aux tests d'intelligibilité dans le bruit révèlera que les reconstructions restent cohérentes/complémentaires au signal sonore, comme un bon playback, sans que ne soient forcément transmises les spécificités articulatoires du locuteur réel.
Pour une évaluation plus quantitative de cette fidélité - importante lorsqu'on s'attend à reconnaître un locuteur que l'on a déjà fréquenté, et qui fait toute la différence entre un clone et un avatar vaguement ressemblant - on peut souhaiter vérifier que les mouvements du visage et des lèvres, ou leur image, restent fidèles à ceux du message original. Les corpus proposés tentent de satisfaire à cette exigence.
Les corpus qui vont être énumérés ont souvent été créés ou enregistrés spécifiquement pour la tâche d'évaluation. Pour tous, on possède une connaissance a priori :
Dans ces cas où des valeurs sont connues, on pourra juger de la fidélité au message original à travers des critères objectifs, puisque les erreurs de mouvements de points du visage ou leur image seront calculables. Dans les autres, on confirmera plutôt que la codage/décodage est adapté à une tâche de télécommunication.
Des prises de vues telles que celles de la figure II.1 correspondent à l'application visée : un visage sans maquillage ni marqueur, filmé de face par une caméra solidaire de la tête. De nombreuses séquences, avec des conditions très variées (position et réglages de la caméra, qualité et teinte de l'éclairage) ont été enregistrées avec les locuteurs clonés. On peut facilement en capturer de nouvelles : il suffit de disposer du locuteur original.
 |  |
Ces séquences ne sont hélas pas idéales pour des évaluations quantitatives, puisqu'on ne dispose pas des paramètres d'articulation et de position «idéaux». On peut cependant vérifier «subjectivement» que l'animation 3D reconstruite est un doublage plus qu'acceptable de la piste son originale, et comparer par rapport au signal visuel original les résultats d'intelligibilité dans le bruit d'un panel de sujets. Sur des séquences analysées, on peut aussi vérifier les connaissances phonologiques et leur correspondance avec la piste son. Ces approches ne permettront pas d'analyser où est localisée l'erreur de reconstruction, ni de la mesurer : on ne pourra donc pas quantifier la fidélité au locuteur.
Sur les images qui ont servi à la construction des clones (Cf. figure II.2), les paramètres idéaux (au sens des moindres carrés) du modèle (articulation et orientation de la tête) sont par contre connus, puisque l'on dispose des coordonnées des points 3D matérialisés par les billes : sans minimisation complexe et itérative, les paramètres s'obtiennent directement en exploitant le modèle articulatoire de déplacement qui est linéaire.
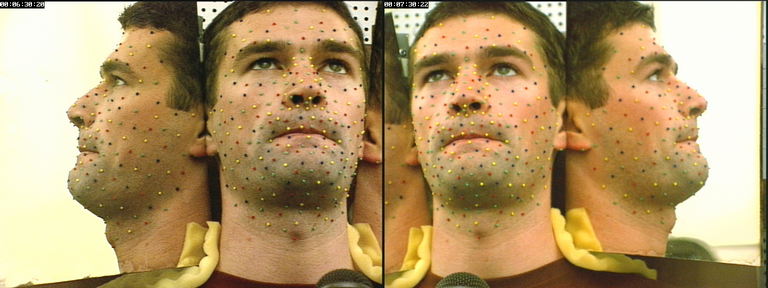
Fig II.2 : Un des visèmes, hyper-articulé, de l'apprentissage
Ce corpus peut donc sembler intéressant pour l'évaluation, d'autant qu'on dispose de nombreux visèmes pour tous les locuteurs clonés. Mais il n'est lui non plus pas parfaitement adapté : même si l'on ne considérait qu'une caméra, on reste très loin de la situation de la labiophonie puisque le visage est couvert de billes qui révèlent l'articulation sous-jacente. De plus, le champ de la parole est volontairement délaissé au profit d'un nombre fini de visèmes arrêtés et hyper-articulés. Enfin, même s'ils ont servi à l'apprentissage, le modèle ne peut normalement pas les atteindre parfaitement (les 6 paramètres couvrent 96% de la variance réelle) ni synthétiser exactement leur apparence (variation de lumière...) !
Les visèmes de l'apprentissage étaient hyper-articulés : l'hypothèse implicite de quasi-linéarité et donc de convexité de l'espace articulatoire réel amène à plutôt explorer des sommets potentiels de cet hyper-volume. Il faut donc vérifier que la parole naturelle, continue, peut effectivement être représentée avec les modèles linéaires obtenus. C'est l'intérêt des séquences vidéos réalisées dans les conditions de l'apprentissage (billes et caméras multiples), qu'illustre la figure II.3.
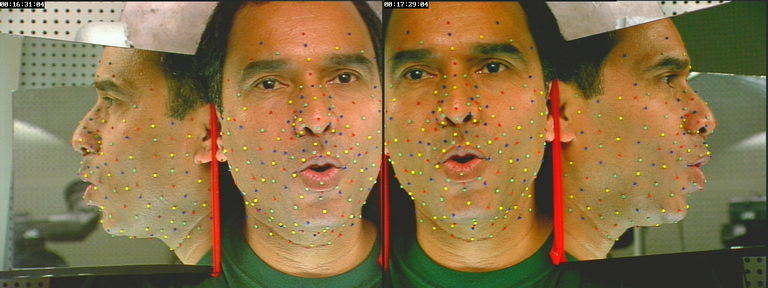
Fig. II.3 : Vidéos de parole naturelle, avec les billes de l'apprentissage
Ces corpus ont forcément du être enregistrés en même temps que les visèmes de création de clones pour que les billes soient précisément aux mêmes endroits. Avec ces séquences, on peut avoir accès aux déplacements 3D des points modélisés, pour peu que les très nombreuses billes soient cliquées. Cela permettra de vérifier que les postures de la parole naturelle, où interviennent des phénomènes complexes tels que l'anticipation et la co-articulation, sont incluses dans l'espace atteignable du modèle linéaire construit seulement à partir de quelques visèmes hyper-articulés.
Pour s'astreindre des billes sans perdre la connaissance des paramètres à retrouver à l'analyse, le plus simple est de générer des visèmes ou des séquences synthétiques, comme l'illustre la figure II.4. On peut bien sûr générer a posteriori toutes les séquences de test voulues.

| 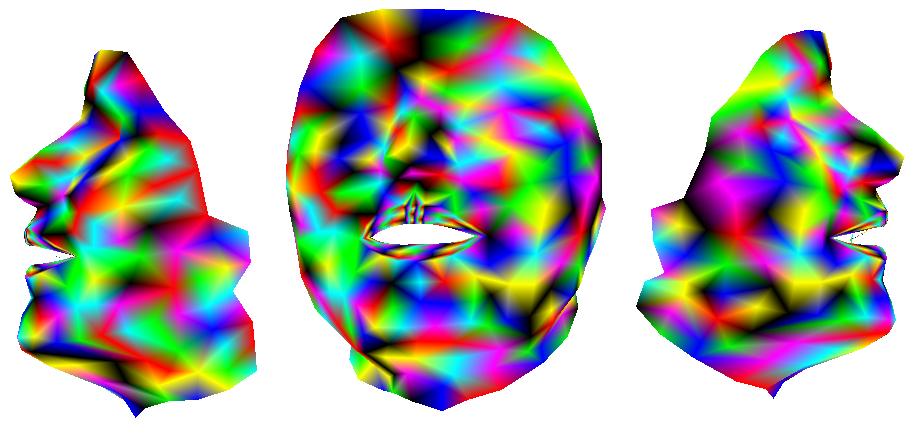
|
Comme ces visèmes ont été synthétisés, on connaît d'avance les paramètres (articulatoires et positions) qui leur correspondent. On sait aussi que ces images correspondent exactement à des états synthétisables. On peut jouer sur la texture utilisée (hyper-texturée ou naturelle) pour étudier l'influence du grain, ou du bruit vidéo, sur les paramètres que donnera l'analyse. Seul problème, les paramètres qui ont servi à la synthèse ne correspondent pas forcément à des articulations naturelles (cas de paramètres aléatoires) ou à tout l'espace réel d'articulations (si on utilise des résultats d'inversion).
Ce type de corpus est donc idéal pour valider la phase de minimisation, puisqu'on isole un maximum des autres facteurs, mais s'éloigne plus qu'il ne semblerait visiblement de l'application réelle de labiophonie.
Le corpus parfait de test n'existe donc pas. Pour complémenter les précédents, lors de l'enregistrement du dernier clone créé, le visage avait de plus été filmé avec une prise de vue de type de labiophonie alors qu'avait déjà été collé un sous-ensemble des billes qui serviraient à l'enregistrement des visèmes. La zone des lèvres ne comporte aucune bille, comme on peut le voir sur la figure II.5.
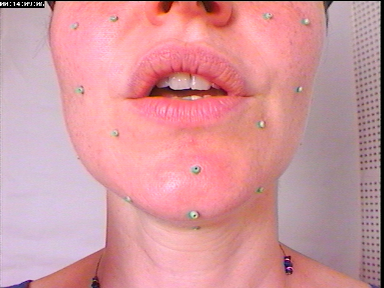
Fig. II.5 : Prise de vue rapprochée avec un sous-ensemble des billes de l'apprentissage
C'est le corpus de contrôle le plus proche des conditions de l'application : grâce au très petit nombre de billes visibles, qui font partie du modèle de construction du clone, on est capable d'inverser plus formellement (sans texture ni synthèse) l'articulation et la position du modèle, pour les comparer au résultat de l'analyse/synthèse qui serait réalisée dans les conditions de la labiophonie (rehaussement du contraste de lèvres). Bien sûr, pour que le faible nombre de billes intervienne le moins possible, la texture utilisée par l'analyse ne les modélise pas.
| Type du corpus existant | synthèse ou capture | Nombre de caméras | Billes visibles | hyper- articulé ? | Locuteurs disponibles | Taille du corpus | Valeurs des paramètres |
| Visèmes hyper-texturés | S | au choix | au choix | tous | infini | connus par construction | |
| Visèmes de synthèse | S | au choix | au choix | tous | infini | connus par construction | |
| Visèmes d'apprentissage | C | 4 | ± 200 | Oui | tous | 40 à 120 par locuteur | disponibles (déjà cliqués) |
| Vidéo d'apprentissages | C | 4 | ± 200 | Non | tous | 3 à 60 phrases par locuteur | sous réserve de clics... |
| Vidéos micro-caméra | C | 1 | Non | PB, MEH et HL | + de 50 phrases par locuteur | impossibles à obtenir | |
| Vidéos + billes en micro-caméra | C | 1 | 20 | Non | HL | + de 50 phrases | disponibles (déjà cliquées) |
L'évaluation des méthodes de codage basé objet n'est souvent pas réalisée (ou seulement avec des images des synthèse). Dans le cadre de TempoValse, de nombreux corpus ont été pensés, enregistrés et souvent étiquetés manuellement pour cette tâche. Le volume de données résultant est très important, mais son exploitation est déjà bien avancée.
Cette partie présente les résultats de l'évaluation de la version actuelle de Minnie, pour les différents corpus de tests qui ont été introduits précédemment. On y conclura que l'inversion par analyse/synthèse est numériquement envisageable avec les modèles construits et que l'algorithme du simplexe est un bon candidat pour la minimisation. Avec l'évidence sur les corpus de test que la convergence vers le résultat attendu est acceptable avec un nombre d'itérations limité, on présentera les ordres de grandeur des erreurs sur les paramètres inversés ou du résidu après la reconstruction.
Pour que les algorithmes d'optimisation soient efficaces, la fonction d'écart e doit a priori posséder certaines propriétés, notamment l'existence d'un minimum atteignable aux valeurs théoriques des paramètres. Une telle validation théorique serait une propriété forte, mais probablement impossible à dériver formellement. À défaut, on peut néanmoins conduire une première vérification expérimentale : des échantillons de e ont été collectés autour de la position neutre, pour deux modes de rendu de synthèse (cf. Fig. II.4) :
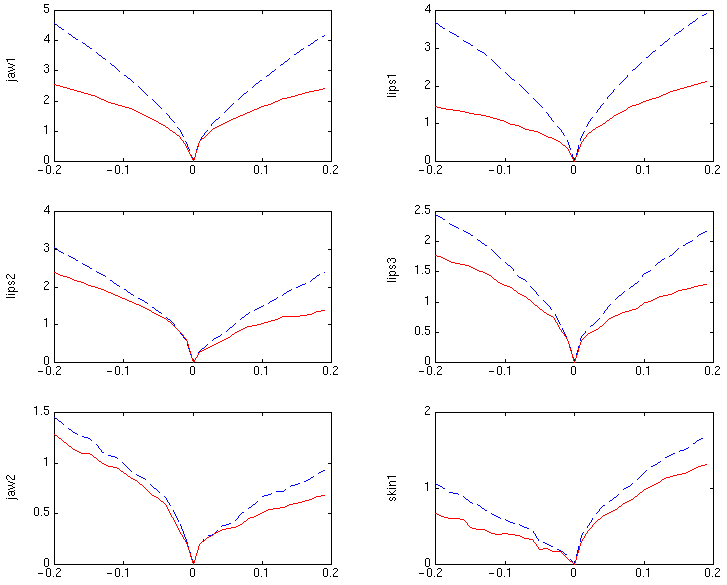
Fig. III.1 : Valeurs de l'erreur
e pour des variations autour de la position neutre de chaque
paramètre articulatoire,
avec un rendu hyper-contrasté (lignes en tirets) et avec les
textures photo-réalistes (lignes continues)
Avec le rendu hyper contrasté, les vallées de e sont plus marquées et ne contiennent que peu de minima locaux (Cf. figure III.1). Cela suggère que le minimum global est plus facilement atteignable, au point qu'on pourrait être tenté d'utiliser des algorithmes de minimisation avec calcul ou estimation du gradient.
Cependant, la présence importante de minima locaux avec le mode de rendu photo-réaliste peut expliquer a posteriori pourquoi les techniques d'optimisation locales sont moins efficaces que l'algorithme du simplexe de Nelder-Mead. De plus, et comme prévu, les amplitudes de variation plus faibles pour les paramètres jaw2 et skin1 (qui expliquent peu de la variance des données) semblent indiquer que ces paramètres seront plus difficiles à estimer précisément.
Durant le projet, de nombreuses vidéos ont été analysées puis re-synthétisées avec la plate-forme Minnie. Présentées avec leur piste son originale, ces reconstructions 3D animées sont généralement jugées subjectivement comme satisfaisantes : elles s'apparentent à des doublages corrects. Examinons quelques critères qualitatifs plus objectifs.
On sait (partie gauche de la figure III.2) que face à un signal audio de parole de plus en plus bruité, l'intelligibilité est meilleure et décroît moins vite si l'on peut voir les lèvres ou le visage du locuteur réel. C'est la cohérence et la complémentarité audio-visuelle de la parole qui permet ce gain d'intelligibilité. Ce gain doit pouvoir être constaté sur des visages 3D si leur articulation est suffisamment correcte. Cela a déjà pu être vérifié (partie droite de la figure III.2), avec des scores sensiblement plus faibles, pour des images de synthèse assez sommaires (lèvres 3D, modèle de visage grossier).
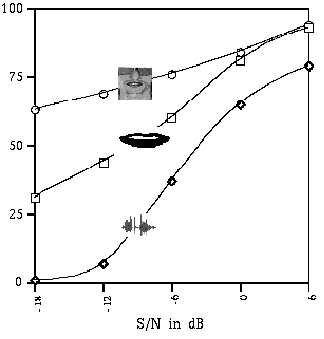 | 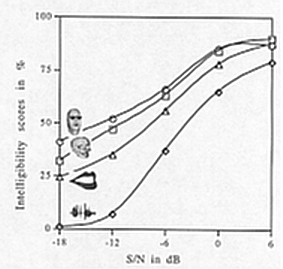 |
Dans le cadre du projet TempoValse, une nouvelle campagne de tests a pu être préparée : un corpus spécifique, de 40 numéros de téléphone (la moitié en parole chuchotée, l'autre moitié en parole normale) a été enregistré, avec la locutrice HL. Les stimuli visuels qui ont été créés comporteront cette fois le modèle de la dentition présenté dans le rapport SP2 T5.
L'algorithme a été utilisé pour analyser une séquence vidéo complète (vue de face et de profil, avec les billes de l'apprentissage, comme sur la moitié gauche de la figure II.3) : la posture articulatoire et le mouvement de la tête ont été suivis à 50 Hz sur une séquence vidéo de 36 secondes de la fable «La bise et le soleil». Le jeu final de paramètres obtenu sur une image donnée était utilisé sur l'image suivante comme le centroïde du simplexe initial.
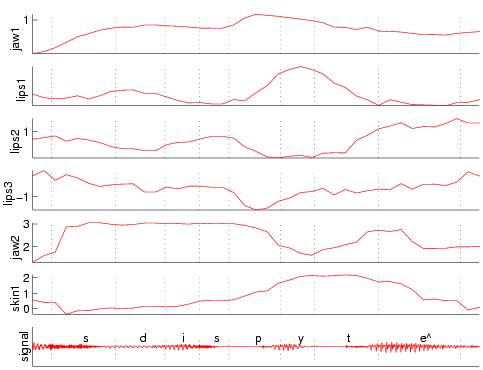
Fig. III.3 : Suivi des paramètres sur l'extrait « se disputaient ».
Un extrait des résultats de suivi est disponible sur la figure III.3. Les paramètres évoluent assez régulièrement, et en accord avec la phonétique articulatoire : pour [y], on observe une franche protrusion (paramètre lips1) conjuguée à une faible rétraction de la mâchoire. La remontée de la mâchoire (jaw1) est maximale pour le [p].
La vitesse de convergence de Minnie dépend bien sûr de l'image analysée, du critère d'arrêt utilisé pour le simplexe, ainsi que du volume initial du simplexe (fixé à 1.0). Le critère d'arrêt (distance maximale entre les sommets du simplexe inférieure à 10-4 et écart entre les valeurs associées plus faible que 0.05) a été figé sur une base d'apprentissage où les résultats attendus étaient connus. Relâcher les contraintes de ce critère perturberait donc probablement la qualité de l'analyse.
Avec les réglages proposés dans Minnie, la fonction d'erreur a été appelée 214 fois en moyenne par image pour la séquence «la bise et le soleil» avant que le critère de convergence ne soit atteint, ce qui est probablement compatible avec le temps réel, sous réserve d'une accélération matérielle : du rendu graphique, mais surtout du calcul de la différence d'images.
Nous nous plaçons maintenant dans les conditions qui ont été retenues dans le cadre de TempoValse pour la labiophonie : le locuteur n'a aucun marqueur sur son visage, et il est filmé par une seule caméra, solidaire de la tête et calibrée. Seuls les paramètres articulatoires auront besoin d'être évalués à chaque image.
On ne présentera pas (Cf. SP2, T3) de nouveau le principe du rehaussement du contraste entre les lèvres et les autres parties du visage (peau) qui est utilisé dans ce cas : l'analyse est axée sur les lèvres, parce qu'elles sont prédominantes dans ce type d'image, où le locuteur peut être vu avec peu de contraste et des conditions d'illumination très différentes. Rappelons seulement que c'est cet articulateur qui transmet le plus grand nombre d'informations sur les mouvements faciaux, ce qui est bien retranscrit dans le modèle articulatoire.
 | 
|
Comme précédemment, on a bien sûr cherché à vérifier sur plusieurs séquences vidéos que les trajectoires des paramètres articulatoires étaient régulières et que les mouvements du visage recouvrés étaient phonétiquement pertinents : c'est effectivement le cas, mais les deux paramètres les plus faibles (jaw2 et lar1) semblent très bruités, du fait de la caméra unique et/ou de l'absence de marqueurs. Dans ces même conditions, on a pu vérifier que l'optimisation de l'orientation de la tête ne fonctionnait pas (bruit important à l'inversion).
Subjectivement, les résultats de suivi (cf. figure III.4 pour un exemple d'image) montrent que dans ces cas difficiles (une seule caméra, pas de marqueurs) l'analyse par la synthèse des seuls paramètres articulatoires continue de fournir des résultats exploitables, qui méritent donc d'être évalués.
Les premières expériences ont été conduites sur des données de synthèse, en utilisant les modes de rendu précédents (hyper-texturé et photo-réaliste), avec dans certains cas l'ajout d'un bruit blanc sur les images analysées (le maximum des perturbation était 10, pour chaque plan couleur 8 bits).
Les résultats sont présentés sur la figure III.5 et dans la partie gauche de la table III.1.
| Rendu hyper-texturé | Hyper-texturé + bruit | Textures naturelles | Text. nat. + bruit | Visèmes avec billes | ||
| Jaw1 | 0.014 | 0.017 | 0.049 | 0.026 | 0.076 | |
| Lips1 | 0.007 | 0.007 | 0.029 | 0.018 | 0.16 | |
| Lips2 | 0.029 | 0.033 | 0.075 | 0.053 | 0.22 | |
| Lips3 | 0.015 | 0.019 | 0.073 | 0.055 | 0.29 | |
| Jaw2 | 0.19 | 0.29 | 0.41 | 0.26 | 0.59 | |
| Skin1 | 0.094 | 0.11 | 0.22 | 0.16 | 0.47 | |
| e | 0.91 | 1.74 | 0.88 | 1.25 | 1.62 | |
| 3D RMS | 0.008 | 0.010 | 0.020 | 0.014 | 0.073 |
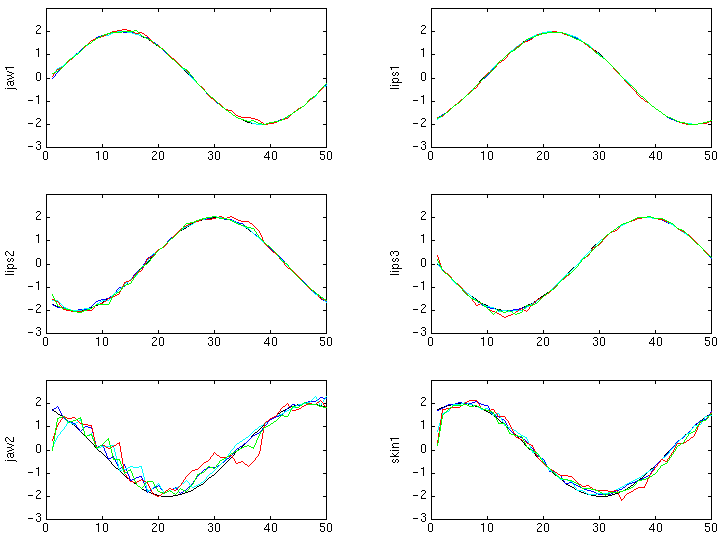
Fig III.5 : Estimation des paramètres (valeur
de référence en noir) d'après des images de
synthèse :
avec rendu hyper contrasté en présence (en cyan)
ou non (en bleu) d'un bruit blanc,
ou obtenues en rendu texturé en présence (en vert)
ou non (en rouge) d'un bruit blanc.
Même pour l'analyse d'images synthétisées avec les textures cylindriques et du bruit, le système est capable de retrouver les mouvements 3D. L'ajout de bruit augmente les valeurs résiduelles de e, mais sans vraiment interférer sur les estimations des paramètres. Cela est peut-être dû au bruit inhérent à la phase de synthèse en elle-même (sous- puis sur-échantillonnage des textures, discrétisation des coordonnées, artefacts de rendu par OpenGL, etc.).
On opère ici sur les images de visèmes qui ont servi à construire les clones (comme sur la figure II.2). La procédure d'inversion bénéficiera des billes collées sur le visage du locuteur, qui augmentent la richesse de la texture, et des vues de face et de profil, qui reflètent le caractère 3D de l'information. L'analyse utilise un modèle de synthèse où la texture inclut les billes. Il n'y a pas de rehaussement du contraste lèvres/peau, les fonctions de pré-traitement f dans l'équation 1 ne font que normaliser les données RGB par leur luminance.
Les mouvements de tête estimés précisément pendant la construction du modèle ont été utilisés ; seuls les paramètres articulatoires ont été recherchés, en utilisant ceux de la posture neutre comme conditions initiales. Comme on peut le voir sur la colonne de droite de la table III.1 et sur la figure III.6, l'analyse a pu retrouver les paramètres articulatoires de référence (résultats issus de la construction du modèle). Le résultat est cependant moins précis pour les deux paramètres jaw2 et skin1. L'erreur image est quasi-constante (inférieure à 2 pour des plans couleurs 8 bits), avec des valeurs plus faibles pour les trois visèmes [a], [afa], [upu] sur lesquels les textures utilisées pour le rendu ont été extraites. On peut voir sur le graphe de l'erreur RMS 3D correspondant aux vrais paramètres que les valeurs sont non-nulles (traduisant la couverture du modèle à 96% de la variance), mais que la plupart d'entre elles sont centrées autour de 0.1 cm : le modèle capture bien les spécificités du locuteur sur chaque visème.
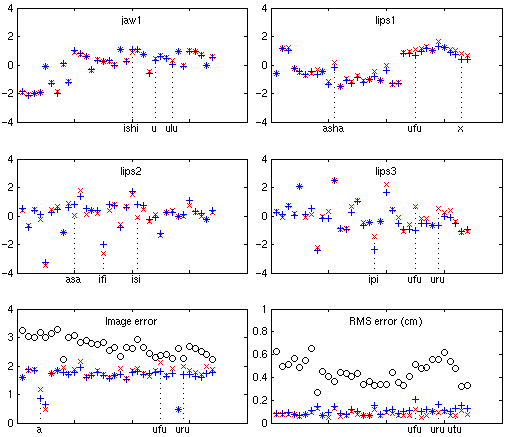
Lignes 1 et 2: paramètres articulatoires estimés (+)
et réels (x) pour chaque visème.
Ligne 3 : erreurs pour chaque visème. Les distances à la
posture neutre sont données pour indication (o).
Sous chacun des graphiques, les noms des trois plus mauvais
visèmes sont indiqués.
Fig. III.6 : Inversion articulatoire pour les visèmes de
l'apprentissage du modèle
En plus des classiques évaluations qualitatives, un certain nombre d'évaluations quantitatives complémentaires ont pu être planifiées et menées à bien dans le cadre du projet TempoValse. Cela été possible grâce à la disponibilité de vraies trajectoires de points de chair du visage. Cependant, ces corpus introduisaient tous un biais différent dans la procédure d'estimation (présence de marqueurs, parole non naturelle...). Un bon compromis entre la disponibilité de marqueurs de référence et la caractérisation sans biais des déformations faciales a peut-être été trouvé lors de la construction du dernier clone, celui de la locutrice HL : on a enregistré un corpus où le visage du locuteur n'est marqué qu'avec quelques billes (cf. figure II.5), suffisantes pour inverser directement de manière robuste le modèle articulatoire. On note que la principale région d'intérêt (les lèvres) est laissée vierge. Dans le cadre du projet TempoValse, ces séquences ont déjà été étiquetées (pointage manuel de toutes les billes, image par image) par un expert. L'exploitation de ces données de référence va permettre de bientôt analyser les résultats de l'inversion par analyse/synthèse dans un cadre très proche de celui de l'utilisation prévue par le projet de la labiophonie.
Les codages basé objet, tels que la labiophonie, sont difficiles à évaluer de façon objective, et cela est rarement réalisé. Pour la labiophonie, nous avons effectué plusieurs évaluations systématiques de notre méthodologie de suivi basée sur le paradigme d'analyse par la synthèse, produisant (et étiquetant) pour cela un volume conséquent d'images, répartis en différents types corpus, dont certains restent encore à exploiter pleinement. En plus d'évaluations qualitatives, les paramètres de contrôle et les reconstructions 3D ont été quantitativement vérifiés à la fois sur des données de synthèse et sur des données réelles et valident un certain nombre d'utilisations de la labiophonie.
Cette évaluation objective devrait être rapidement complétée par de nouveaux résultats subjectifs de perception, pour vérifier que les paramètres inversés conservent les bonnes propriétés de la communication audio-vidéo, en effectuant des mesures de gain d'intelligibilité dans le bruit avec les derniers clones créés. Les corpus (naturels et re-synthétisés) prévus pour la perception des numéros de téléphone, avec de la voix chuchotée ainsi que de la voix normale, sont prêts à être soumis à un panel de sujets, dans les conditions spécifiques d'un terminal de type labiophonie mobile : synthèse du clone HL texturé, avec dents, sans billes, sur un mini-afficheur LCD en mode portrait, interlacé, au format PAL.