A realtime voice modification system
GFM-Voc (Glottal Flow Model-based Vocoder) is the first system that allows high-quality and real-time voice modification, including:
- Articulation manipulation: simulate a change of jaw, tongue and lip positions
- Voice quality manipulation: change the perceived voice force or tenseness
The system is based on the implementation of a newly developed source-filter decomposition method, called GFM-IAIF, that allows the extraction of both vocal tract and glottis contributions to the speech signal, as compact set of filter parameters. The latter are then controllable through a GUI, before re-synthesis of the speech with the modified parameters. The system requires no training, and operates on any voice, male or female, without tuning. Examples of applications for this system include expressive speech synthesis, by adding the system at the end of a speech synthesiser pipeline ; auditory feedback perturbation to study a speaker's response to modified speech ; and speech therapy.
Related publication
- O. Perrotin, I. McLoughlin (2019)
GFM-Voc: A real-time voice quality modification system
Proceedings of Interspeech, Graz, Austria, September 15-19, pp. 3685-3686. (poster)
Source code
The source code for the GFM-IAIF framework is available on GitHub. More details on GFM-IAIF here.
Demonstration
The following combines text from the paper, and extra-explanations based on the oral presentation at Interspeech (Figure 2).
Towards expressive speech synthesis
Speech synthesis has now reached a point of high naturalness, prompting current research to shift towards expressive speech synthesis [1]. While intonation, stress, and rhythm have been the main features of interest for expressive speech generation, it has been shown that timbre also conveys substantial expressive information, mainly encoded in the glottal signal spectral envelope [2,3]. Efforts to include a parametrised glottis signal in text-to-speech (TTS) vocoders [4] have shown improvements in the expressivity of the synthesised speech [5]. However, with the advance of end-to-end speech synthesis and the use of neural vocoders, the parametrisation of vocal signals has disappeared, leading to a loss of control in many recent synthesis systems. To re-introduce full timbral control into speech synthesis, we propose a real-time vocal modification system called GFM-Voc, that can modify both vocal tract (VT) and glottis parameters of a speech signal without loss of audio quality. While this work demonstrates the modification of a speaker's voice in real-time, GFM-Voc can also post-process speech from any TTS synthesiser, to adjust the voice quality of the synthesised speech.
The extraction of both VT and glottis components is achieved by a source-filter decomposition method called Glottal Flow Model - Iterative Adaptive Inverse Filtering (GFM-IAIF) [6], detailed below. Source-filter decomposition is common practice in speech analysis [7]. Yet, it is not performed in current real-time voice modification systems such as Audapter [8], which modifies the VT by processing the full spectral envelope of the signal that also includes glottis information. By contrast, GFM-Voc is the first system that allows independent extraction of both VT and glottis components in real-time, and we claim that the disentanglement of VT parameters allows more subtle modification. Moreover, it also enables real-time glottis modification, which to our knowledge has not been proposed before.
GFM-Voc framework
The system architecture is depicted in Figure 1, showing speech captured from a microphone, vocoded, and then output in real time. The vocoder begins with decomposition using GFM-IAIF, detailed below, to yield the speech excitation signal, and two filters whose frequency responses correspond to the glottis and VT spectral envelopes, respectively. Then, the filters parameters are modified as controlled via a Graphical User Interface (GUI). Speech is finally re-composed by filtering the excitation with the new glottis and VT filters, respectively. The system is coded on Matlab using the Audio Toolbox and sampled at 44.1 kHz to ensure high quality audio. It has a latency of 46 ms on a 2012 model MacbookPro with Intel i7 processor.
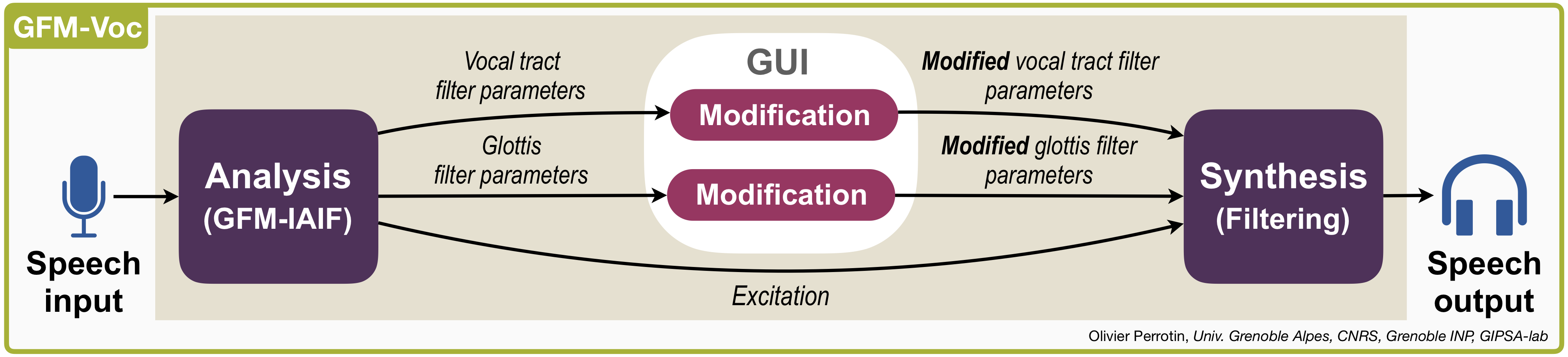
Figure 1: Flowchart of GFM-Voc
Modification of voice parameters
GFM-IAIF for the analysis-synthesis framework
Acoustic speech production theory describes speech as formed by an excitation passing through a first filter G describing the glottis signal spectral envelope, and a second filter VT that describes the vocal tract spectral envelope [9]. It has been shown that the glottis spectral envelope can be modelled by a 3rd order filter that combines a resonance called the glottal formant (described by its central frequency FGF and bandwidth BGF), and an additional low-pass filter called spectral tilt (described by its cutting frequency FST) [10]. The VT filter is described by a set of resonances, called vocalic formants, described by their centre frequencies Fi and bandwidths Bi.
The GFM-IAIF source-filter decomposition method [6] allows the excitation, G filter, and VT filter, to be disentangled from the speech signal. The filters are described by sets of LP coefficients of order 3 and 46 for G and VT, respectively. Figure 2 shows an example of filter extraction. The top-left panel displays the spectrum of a speech frame, with its full LPC envelope. The top-right panel shows the independent extracted VT and G envelopes, in thick purple. One can see that the vocal tract envelope has no spectral tilt but only resonances, whose central frequencies Fi are displayed. By contrast, the glottis filter shows the low frequency resonance and the high frequency attenuation, with their respective parameters FGF and FST.
Once the filters extracted, they are converted to equivalent analogue filters, computed using the bilinear transform [11], so as their modification is stable. The top-right of Figure 2 shows examples of filter modification. VT modification is shown in green: the first formant was shifted downwards, and the second and third upwards. Then the filter is reconstructed and plotted from these new parameters. Then, two examples of glottis manipulation are presented: in blue is the modification for a softer and more laxed voice; in red is the modification for a louder and more tensed voice. It has been shown [10] that a laxed voice is characterised by a more sinusoidal oscillation of the vocal folds, and therefore a narrower glottal formant centred around the first harmonic. Thus, a joint decrease in FGF and BGF simulates a more laxed voice, as shown in Figure 2. Inversely, a more tensed voice is obtained by increasing FGF and BGF. Then, a higher vocal force leads to a sharper closure of the vocal folds, creating high frequency harmonics in the spectrum [10]. Therefore, a joint increase in FGF and FST leads to the perception of higher vocal force, and inversely. The bottom panel of Figure 2 displays in thick purple the glottal flow extracted from the speech signal after the removal of the vocal tract filter. In blue and red are the resulting glottal flows obtained after the glottis filter modifications described above. We note that the softer and more laxed voice modification results in a more sinusoidal glottal flow, while the louder and more tensed voice leads to a more asymmetrical glottal flow, with sharper closure instants. Thus, the spectral modification correlates well with the changes of waveshape that are expected physiologically.
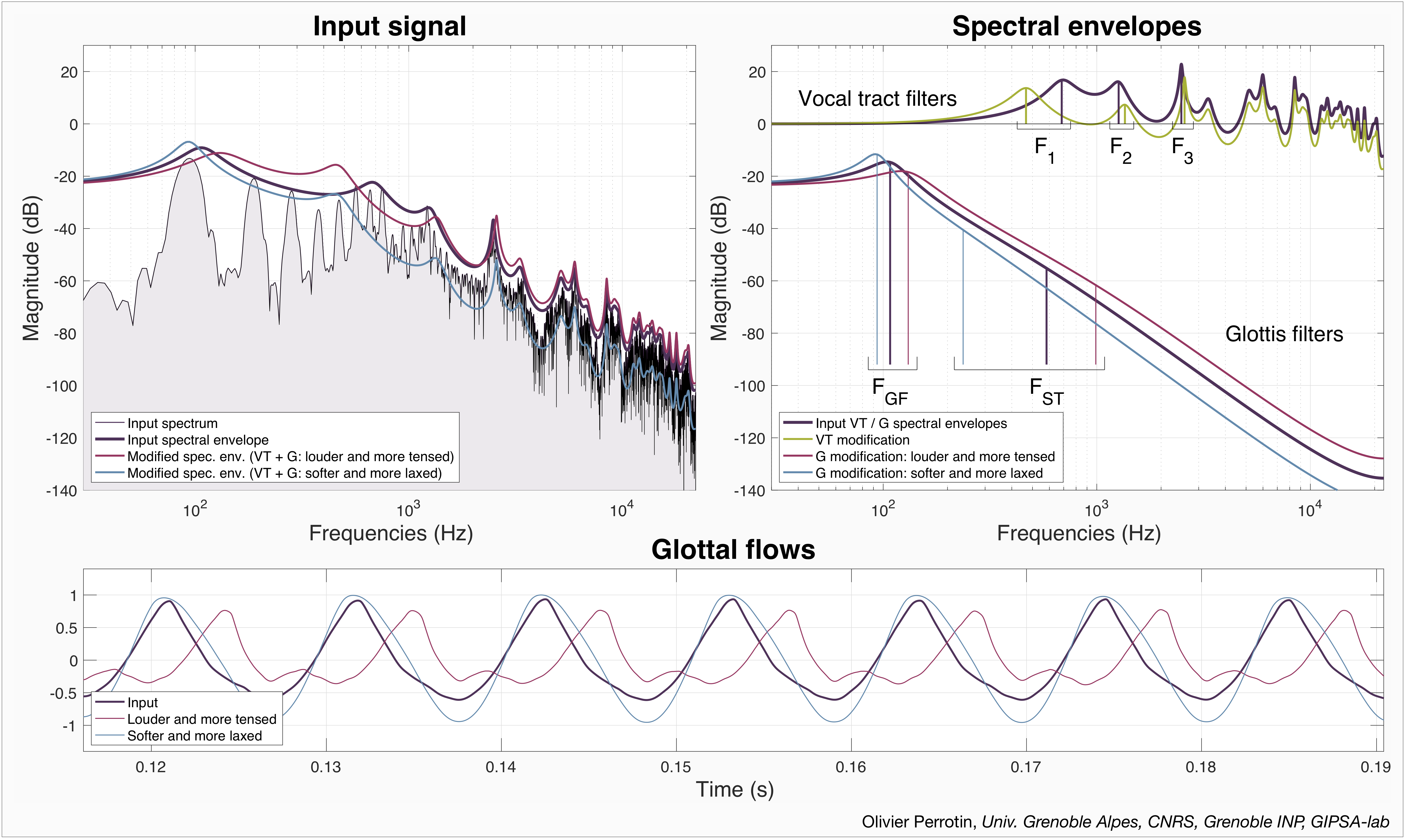
Figure 2: Modification of filter parameters
User Interface
A GUI, shown in Figure 3, has been designed to allow real-time filter parameter modification. Basic controls are provided for the sake of demonstration, but could easily be replaced with more sophisticated VT and glottis parameter transformations.
The right panel of Figure 3 shows the VT filter control. It includes the shifting of the three first formants, that are responsible for vowel perception: the first, second and third formants being roughly linked to jaw opening, tongue position (back-front), and lip rounding, respectively. Each formant shift is controlled using a logarithmic scale to account for the log-perception of frequencies, and each formant can be shifted from the previous to the next one. The plot in the lower right shows an example of VT modification operating on the input filter (in purple). The output filter (in pink) has the 1st formant shifted downwards and the next two shifted upwards.
The left panel of Figure 3 shows the G filter control. Two sets of parameters are available. First, a low-level control allows modification of the glottal formant frequency FGF, its quality factor QGF = FGF / BGF, and the spectral tilt cutting frequency FST. Again, frequencies are shifted on a logarithmic scale. Then, it is possible to control two high-level parameters: vocal force and tenseness, that are linked to FGF, BGF, and FST as explained in the previous section. These relations have been implemented from the Cantor Digitalis real-time singing synthesiser rules [12]. While the high-level parameters enable the control of physiologically-like parameters, the low-level parameters allow direct control of the glottis to explore the capacity of the model for unconstrained voice modification. The bottom left plot in Figure 3 shows an example of voice quality modification (in pink) of the input glottal filter (purple) to lower vocal force and increased tenseness. This leads to a flatter and higher glottal formant, and a lower spectral tilt cutting frequency.
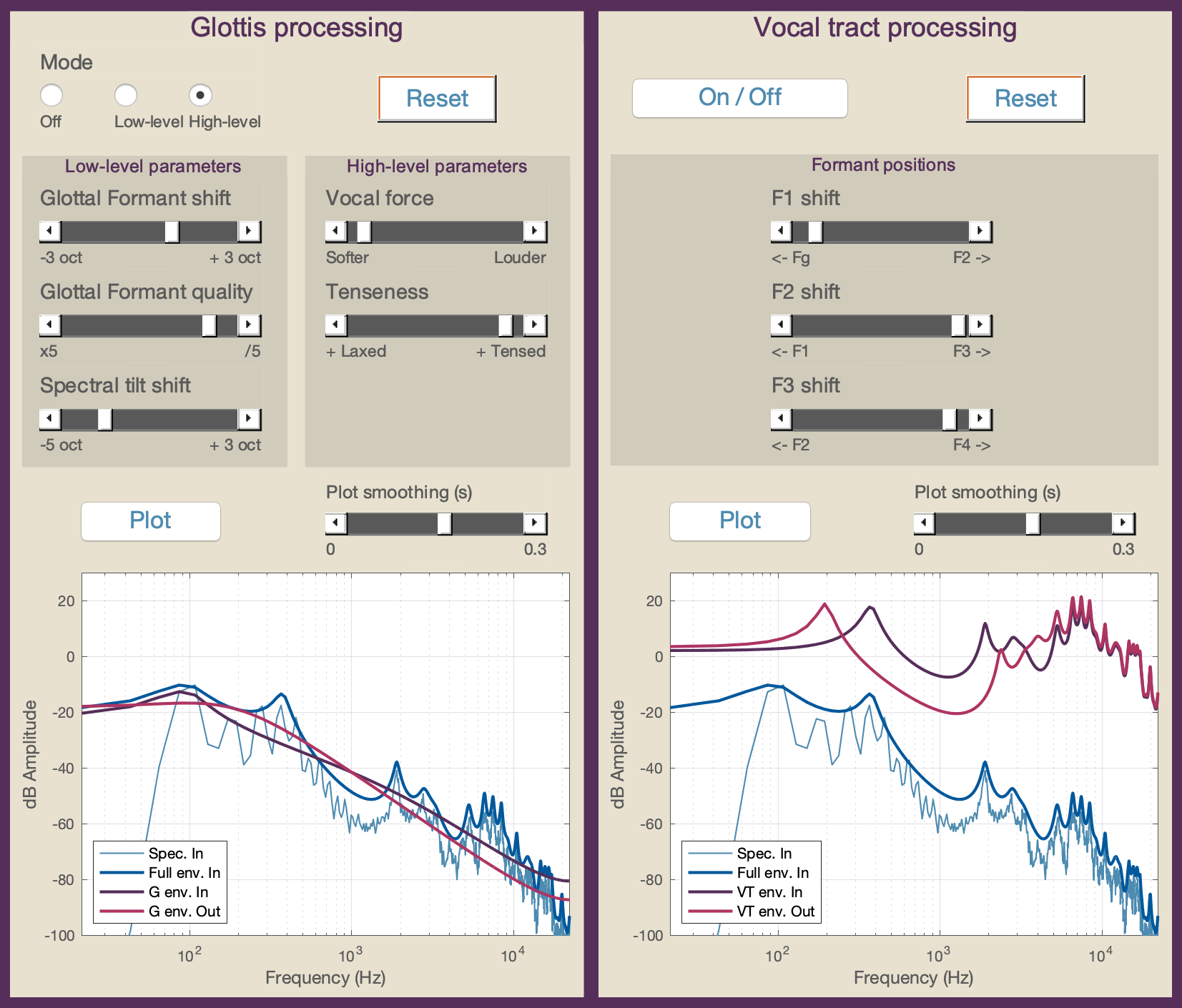
Figure 3: User interface
Conclusion
GFM-Voc is the first framework allowing high-quality and real-time controlled modification of both vocalic formants and voice quality. It can benefit the study of responses to auditory feedback perturbation [13], and has great potential as a post-processor for speech output from expressive speech applications, including TTS. Future developments include excitation signal modification, and more sophisticated high-level rules for filters parameter control.
References
Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis
Proc. of Machine Learning Research, Stockholm, Sweden, July 10-15 2018, pp. 5180–5189.
Vocal quality factors: Analysis, synthesis and perception
J. Acoust. Soc. Am., 90(5), pp. 2394–2410.
The role of voice quality in communicating emotion, mood and attitude
Speech Communication, 40(1), pp. 189–212.
GlottDNN — a full-band glottal vocoder for statistical parametric speech synthesis
Proc. of Interspeech, San Francisco, CA, USA, September 8-12, pp. 2473–2477.
Towards glottal source controllability in expressive speech synthesis
Proc. of Interspeech, Portland, OR, USA, September 9-13, pp. 1620–1623.
A Spectral Glottal Flow Model for Source-Filter Separation of Speech
Proc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, May 12-17, pp. 7160-7164. (poster)
Openglot – an open environment for the evaluation of glottal inverse filtering
Speech Communication, 107, pp. 38–47.
Exploring auditory-motor interactions in normal and disordered speech
Proc. of Meetings on Acoustics, Montreal, Canada , June 2-7, pp. 1–8.
Acoustic Theory of Speech Production
Mouton.
The spectrum of glottal flow models
Acta Acustica united with Acustica, 92(6), pp. 1026–1046.
Audio-eq-cookbook
Online
Cantor Digitalis: Chironomic Parametric Synthesis of Singing
EURASIP Journal on Audio, Speech and Music Processing, 2017(2).
Adaptive auditory feedback control of the production of formant trajectories in the mandarin triphthong /iau/ and its pattern of generalization
J. Acoust. Soc. Am., 128(4), pp. 2033–2048.
Grenoble Images Parole Signal Automatique laboratoire
UMR 5216 CNRS - Grenoble INP - Université Joseph Fourier - Université Stendhal