General approach
My approach is to study speech as a multimodal and embodied phenomenon through the following steps:
- design experimental setups to acquire acoustic, articulatory, visual and physiological signals;
- develop machine-learning models able to relate these signals to linguistic, motor or perceptual representations;
- integrate these models into interactive systems, such as assistive spoken-communication technologies or humanoid robots, that enter the sensory-motor loops regulating human communication.
The applications of my work include:
- the development of voice technologies for people with spoken-communication disorders;
- the improvement of robots' socio-communicative abilities;
- the study, through modeling and simulation, of cognitive mechanisms involved in language and speech acquisition.
Computational modeling of speech perception, production and acquisition mechanisms
Objectives
- Explore how sensory-motor, physical and social interactions shape language and speech learning.
- Understand how these interactions can be used to improve the efficiency and adaptability of conversational AI.
Main results
- Development of a neural computational model of vocal imitation enabling self-supervised learning of speech sensory-motor relationships, in particular acoustic-articulatory relationships.
- Evidence for the role of motor inference in the discovery of phonetic units.
- Evidence for the role of invariant acoustic representations in articulatory learning.
- Study of universal phonetic biases for few-shot acoustic unit discovery.

Self-supervised vocal imitation model: learning relationships between perception, articulatory gestures and speech production.
Publications
- Hueber T., Tatulli E., Girin L., Schwartz J.-L. (2020), Evaluating the potential gain of auditory and audiovisual speech predictive coding using deep learning, Neural Computation, vol. 32, no. 3, pp. 596-625.
- Georges M.-A., Lavechin M., Schwartz J.-L., Hueber T. (2024), Decode, Move and Speak! Self-supervised Learning of Speech Units, Gestures, and Sound Relationships Using Vocal Imitation, Computational Linguistics, vol. 50, no. 4, pp. 1345-1373.
- Lavechin M., Hueber T. (2025), From Perception to Production: How Acoustic Invariance Facilitates Articulatory Learning in a Self-supervised Vocal Imitation Model, EMNLP, pp. 23852-23863.
- Ortiz A., Khentout M., Benchekroun Y., Hueber T., Dupoux E. (2026), MauBERT: Universal Phonetic Inductive Biases for Few-Shot Acoustic Units Discovery, ACL.
Context: DevAI&Speech chair (MIAI Cluster), Bayesian Cognition and Machine Learning for Speech Communication chair (MIAI), ERC Speech Unit(e)s, Marvin Lavechin's postdoctoral work, Marc-Antoine Georges's PhD, Angelo Ortiz's PhD.
Speech representation learning
Objectives
- Learn rich, interpretable and controllable representations of speech and audio signals in a self-supervised or weakly supervised way.
- Use these representations for enhancement and restoration of pathological speech.
Main results
- Theoretical formulation of a new class of self-supervised models: Dynamical Variational Autoencoders (DVAE).
- Regularization of VAE latent spaces to enable interpretable control of musical timbre, in collaboration with Arturia.
- Development of methods for restoring missing speech segments through speech inpainting.

Speech inpainting architecture: transferring SSL representations to the reconstruction of masked speech segments.
Publications
- Asaad I., Jacquelin M., Perrotin O., Girin L., Hueber T. (2026), Is Self-Supervised Learning Enough to Fill in the Gap? A Study on Speech Inpainting, Computer Speech & Language.
- Girin L., Leglaive S., Bie X., Diard J., Hueber T., Alameda-Pineda X. (2021), Dynamical Variational Autoencoders: A Comprehensive Review, Foundations and Trends in Machine Learning.
- Roche F., Hueber T., Garnier M., Limier S., Girin L. (2021), Make That Sound More Metallic: Towards a Perceptually Relevant Control of the Timbre of Synthesizer Sounds Using a Variational Autoencoder, Transactions of the International Society for Music Information Retrieval.
Context: Fanny Roche's PhD, collaboration with Arturia, Marc-Antoine Georges's PhD, collaborations with INRIA RobotLearn and LPNC.
Silent speech interface
Objectives
- Convert articulated but non-vocalized speech into text or an intelligible acoustic signal.
- Understand and model prosody control in silent speech.
Main results
- First silent-speech communication interface based on the acquisition of articulatory data combining tongue ultrasound and video.

Silent speech interface: multimodal articulatory acquisition and conversion into audible speech.
Publications
- Tatulli E., Hueber T. (2017), Feature extraction using multimodal convolutional neural networks for visual speech recognition, IEEE ICASSP, pp. 2971-2975.
- Hueber T., Bailly G. (2016), Statistical Conversion of Silent Articulation into Audible Speech using Full-Covariance HMM, Computer Speech & Language.
- Hueber T. et al. (2010), Development of a Silent Speech Interface Driven by Ultrasound and Optical Images of the Tongue and Lips, Speech Communication.
Context: my PhD and Eric Tatulli's postdoctoral work.
Automatic processing of gestural languages
Objectives
- Recognize and automate French Cued Speech.
- Synthesize French Cued Speech from text.
- Analyze the temporal coordination between hand movements and lip movements in cued speech.
- Automatically translate French Sign Language (LSF) into text.
Main results
- First complete decoding and synthesis system for French Cued Speech based on a fully neural pipeline.
- Mediapi-RGB corpus for training automatic LSF translation models.

Automatic recognition of French Cued Speech: combining lip, hand and linguistic information.
Publications
- Sankar S., Lenglet M., Bailly G., Beautemps D., Hueber T. (2025), Cued Speech Generation Leveraging a Pre-trained Audiovisual Text-to-Speech Model, ICASSP.
- Sankar S., Beautemps D., Elisei F., Perrotin O., Hueber T. (2023), Investigating the dynamics of hand and lips in French Cued Speech using attention mechanisms and CTC-based decoding, Interspeech.
Context: H2020 Comm4Child project, Sanjana Sankar's PhD.
Incremental text-to-speech synthesis
Objectives
- Reduce the latency of text-to-speech systems.
- Produce natural speech before the full sentence is available.
Main results
- Quantification of the impact of future context on the prosodic quality of neural TTS.
- Prosody improvement using predicted future text.
- Fine-tuning of a GPT model to predict online the presence of contrastive focus on a word during text entry.

Incremental TTS: reducing latency in speech-synthesis-assisted interaction.
Publications
- Stephenson B., Besacier L., Girin L., Hueber T. (2022), BERT, can HE predict contrastive focus?, Interspeech.
- Stephenson B., Hueber T., Girin L., Besacier L. (2021), Alternate Endings: Improving Prosody for Incremental Neural TTS with Predicted Future Text Input, Interspeech.
- Stephenson B., Besacier L., Girin L., Hueber T. (2020), What the Future Brings: Investigating the Impact of Lookahead for Incremental Neural TTS, Interspeech.
- Pouget M., Hueber T., Bailly G., Baumann T. (2015), HMM Training Strategy for Incremental Speech Synthesis, Interspeech.
Articulatory biofeedback for speech therapy
Objectives
- Make articulatory gestures visible to support speech therapy.
- Evaluate the contribution of tongue ultrasound and articulatory models in clinical settings.
- Develop systems able to predict articulatory movements in real time directly from the speech signal.
Main results
- Post-glossectomy rehabilitation protocols using ultrasound visual illustration and feedback.
- Contribution of visual illustration of articulators for post-stroke speech rehabilitation.
- C-GMR algorithm for adapting Gaussian-mixture-regression models to a new speaker.
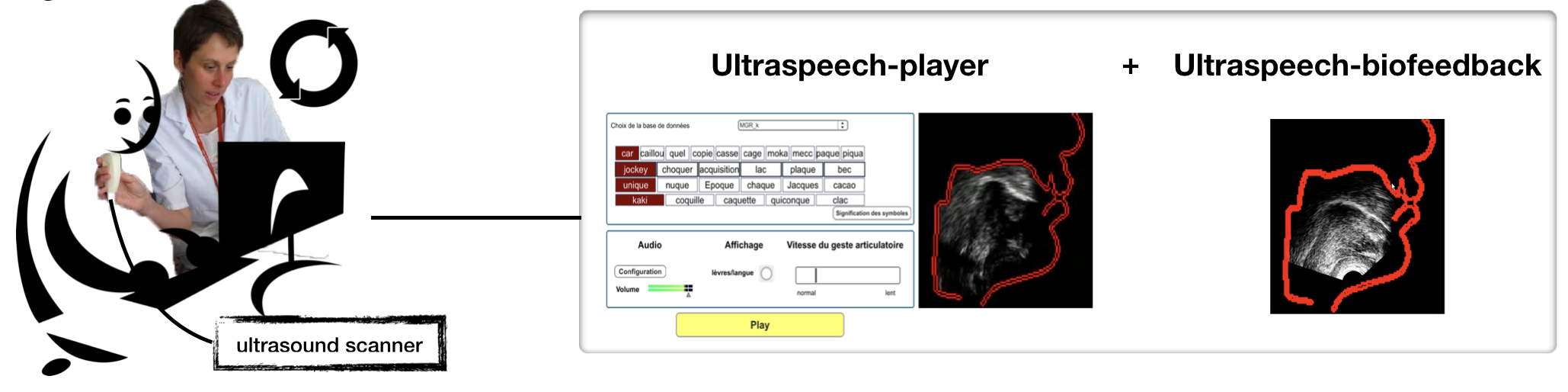
Articulatory biofeedback: making tongue movements visible to support speech therapy.
Publications
- Hueber T., Girin L., Alameda-Pineda X., Bailly G. (2015), Speaker-Adaptive Acoustic-Articulatory Inversion using Cascaded Gaussian Mixture Regression, IEEE/ACM TASLP.
- Girod-Roux M. et al. (2020), Rehabilitation of speech disorders following glossectomy, based on ultrasound visual illustration and feedback, Clinical Linguistics & Phonetics.
- Fabre D., Hueber T., Girin L., Alameda-Pineda X., Badin P. (2017), Automatic animation of an articulatory tongue model from ultrasound images of the vocal tract, Speech Communication.
- Haldin C. et al. (2018), Speech rehabilitation in post-stroke aphasia using visual illustration of speech articulators: A case report study, Clinical Linguistics & Phonetics.
Context: Diandra Fabre's PhD, Marion Girod-Roux's Master's internship, Revison project, Vizart3D project, collaborations with DDL Lyon, Lyon University Hospital, Rocheplane Medical Center, LPNC and INRIA RobotLearn.
Brain-computer interfaces for speech
Objectives
- Explore the restoration of spoken communication from intracranial brain signals (ECoG) related to speech production.
Main results
- Identification of key methodological constraints for designing a speech BCI.
- First demonstration of a real-time, speaker-adaptive acoustic-articulatory conversion system based on electromagnetic articulography.
Publications
- Bocquelet F., Hueber T., Girin L., Chabadès S., Yvert B. (2017), Key considerations in designing a speech brain-computer interface, Journal of Physiology-Paris.
- Bocquelet F., Hueber T., Girin L., Savariaux C., Yvert B. (2016), Real-Time Control of an Articulatory-Based Speech Synthesizer for Brain Computer Interfaces, PLOS Computational Biology.
Context: ANR BrainSpeak and H2020-FETPROACT BrainCom projects, in collaboration with INSERM, Florent Bocquelet's PhD.
For the complete automatically maintained list, see the Publications page. Available software and demonstrators are listed on the Software page.
Grenoble Images Parole Signal Automatique laboratoire
UMR 5216 CNRS - Grenoble INP - Université Grenoble Alpes