Research interests

I'm a member of the CRISSP research team, wich is part of the Speech and Cognition (previously ICP) departement of Gipsa-lab.
There, we study face-to-face communication: synthesis of audio and facial movements, analysis and synthesis of eye movements, pointing gestures, shared attention... Previous application domains included telecommunication systems for example, hearing-impaired people communication (generating cued speech with a 3D hand), as well as social robotics.
For this, we've been working on the creation, representation and coding of animated, textured 3D face clones, also known as "Talking Heads". We now extended our targets/research domain with a talking robot (modified iCub). We also were interested in the communication in shared-reality environnements, to point real or virtual objects, to ease communication between a real human and a robot or a computer agent, with a special interest for the human eye gazes and their relative phasing with the speech segments and the speech turns.
Status and mission
 I'm a permanent CNRS research engineer
since December 2004, having my research activities in the
CRISSP team.
I am also responsible for the development and running of the
MICAL experimentation platform, designed to study face-to-face
spoken communication between two
humans and between a human and a computer, where not only speech, but also
eye gaze, gesture, body posture, and facial expression are involved.
I'm also responsible of the Nina humanoid robot platform, used to collect face-to-face interaction data, create interaction models, and evaluate these models in situated interaction scenarios (using the Furhat robot also for that).
I'm a permanent CNRS research engineer
since December 2004, having my research activities in the
CRISSP team.
I am also responsible for the development and running of the
MICAL experimentation platform, designed to study face-to-face
spoken communication between two
humans and between a human and a computer, where not only speech, but also
eye gaze, gesture, body posture, and facial expression are involved.
I'm also responsible of the Nina humanoid robot platform, used to collect face-to-face interaction data, create interaction models, and evaluate these models in situated interaction scenarios (using the Furhat robot also for that).
Research on cognitive robotics
-
We are studying face-to-face interactions between a humanoid robot and one or several human partners. We are particularly interested in the synchronization between
speech, gaze, pointing gestures, and how it paces turn-taking.
The methodology is to use the immersive teleoperation plaform developped here, as can seen here:
Creating ad hoc interaction scenarios allows us to study and record real interactions between humans and a robot. The following video shows what can be seen and what is beeing looked at by a robot pilot in another immersive teleoperation situation: In this scenario, the pilot that operates the robot interacts with 2 humans, and can use a virtual table (augmented reality) to read and validate data (conducting a game, validating answers and accessing scores results in real-time).
The recorded behaviours can then be modeled, synthesized and evaluated on the same plaftorm.
To discover our teleoperation platform, you can also play the video from Sciences et Avenir available here (by Erwan Lecomte, May 2018).
Research on audio-visual cloning for speech and face-to-face interaction
-
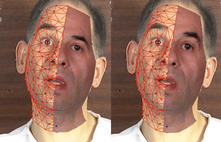
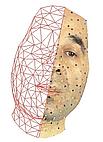
Expanding our previous results on talking heads, we now study natural expressive speech, as found in face-to-face interaction,
including head movement and extended facial gestures, as seen on the following videos.

|
|
|
| |||
| AVI video (22 Mb) | AVI video (15 Mb) | AVI video (11,5 Mb) | AVI video (5,5 Mb) | |||
| A large subset of the beads can be tracked by their appearance. | While capturing the mouth targets and head movements, an articulatory model driven by 7+6 parameters misses the eye brows and forehead gestures (left). The extended articulatory model (right) can recover the facial gestures, using 11+6 parameters. The articulated mesh, half textured, is viewed superimposed on the real video footage. | Another reconstructed sequence. | Another exemple of tracking using the articulatory model. |
I once wrote detailled pages about the Cloning, analysis and synthesis of our Talking heads.
These old pages are full of details and videos. They are still one click away from you.
Current research projects
 |
MULTILEARN (FdF), 2021-2023
Ontogeny of word learning in typical populations: impact of attention and multimodality |
 |
THERADIA (PSCP-PIA, Bpifrance), 2020-2024
Digital therapy at home, with AI |
Completed research projects
 |
Robotex/RHIN (ANR), 2009-2020
Building the Nina humanoid-robot platform, a national platform from the Robotex network, to study natural interactions between humans and a robot. |
 |
RoboTrio (PEPS), 2018+2019
Let our cognitive robot learn how to interview 2 people at the same time to fill a form and guide them. |
 |
SOMBRERO (ANR), 2015-2019
How can we teach a robot to perform a repetitive social task, such as conducting a memory test for elderly people ? |
 |
 CYPASS (Persyval), 2014-2015 CYPASS (Persyval), 2014-2015
Evaluation of the use of a robot body as a remote tutor for a building task.
|
 |
ARTIS (RNRT), 2009-2012
Modelisation and talking heads, in a context of foreign language learning (for pronunciation). |
 |
AMORCES (RNRT), 2008-2011
Collaborating through speech and gaze with a social robot, or screen-displayed agent, to execute a common task. |
 |
TELMA (RNTS), completed in 2009
Exploiting the visual modality of speech to ease communication between hearing impaired and non hearing impaired people. Translating lipreading + Cued Speech towards acoustic speech, and vice-versa through telephone networks. |
 |
ARTUS (RNRT), completed in 2005
Modelisation and synthesis of a cued speech capable 3D talking head, for hearing impaired people in a TV broadcast context. |
 |
HR+ (ROBEA), 2001-2005
Studying a human-robot cooperation scenario, embeding a 3D talking head that is capable of deictic head and eyegaze gestures. |
 |
TempoValse (RNRT), completed in 2002
Prototyping video calling situations, using 3D talking heads as an highly intelligible low-bandwith alternative to video streams. |
Publications
You can browse the full publication list here.
Previous Research Work
Before joining ICP/GIPSA-lab, I got my PhD in the GRAVIR/IMAG lab, where I also worked in computer graphics. You can access my dissertation about teleconferencing scenarios using 3D clones and spatial sound here.