Analyse et synthèse de têtes parlantes
I/ Résumé du principe
II/ Le modèle articulatoire
Pour chaque locuteur, c'est par une nouvelle analyse statistique de positions
articulatoires prototypiques, que l'on va créer un modèle
qui lui soit propre, et dont les paramètres de contrôle correspondront
effectivement à des commandes articulatoires. Ces paramètres
ont une action linéaire, pour mettre en mouvement les points 3D
(du visage, des lèvres) qui constituent le modèle. Cette
collection de points, qui sera par la suite organisée en réseau
de facettes et texturé pour les besoins de la synthèse, peut
être vue comme la combinaison linéaire de quelques modèles
statiques (typiquement, un modèle moyen "au repos" et 2 à
6 modèles "en situation").

1/ Exemple de modèle articulatoire simple
Dans le cadre du système LipsInk de Ganymedia, on trouve un modèle
articulatoire simple, commandé par 2 paramètres : la largeur
et la hauteur de la bouche (mesurées d'après un flux vidéo
où le locuteur a ses lèvres maquillées en bleu). Ainsi, des mascottes ou des logos peuvent être animés en temps-réel :
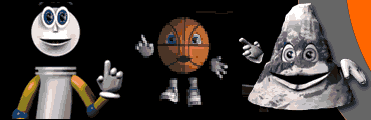
Manifestement, ces paramètres permettent d'animer (de façon
plus ou moins impersonnelle) une bouche (l'ouvrir ou la fermer en synchronisation
avec le son), mais il manque des informations cruciales pour la parole.
En particulier, toutes les positions relatives des dents et des lèvres
(liées aux mouvement de la mâchoire) ne peuvent pas être
codées. Par la méthode de construction proposée pour
le projet Tempo Valse, on va retrouver le besoin de paramètres
supplémentaires, construire un modèle plus précis
et mesurer la différence, notamment pour un auditeur/spectateur.
2/ Création d'un modèle articulatoire précis
Dans cette partie, on explicite l'ensemble de la méthode qui a déjà
été utilisée pour créer plusieurs modèles,
avec 6 paramètres. Dans le cadre du projet, il est prévu
d'étudier un protocole plus léger de création de clones
et de génération des modèles articulatoires.
Parce qu'on cherche à créer un modèle articulatoire
qui soit fidèle à une personne, sa construction se base sur
des mesures 3D et des données images enregistrées. C'est
la nature et l'obtention de ces enregistrements qui va tout d'abord être
précisée.
a/ Méthodologie d'enregistrement
Les modèles sont créés lors d'une séance spéciale
d'enregistrement vidéo des gestes de parole du locuteur, à
qui il est demandé de prononcer 34 phonèmes préétablis
: il s'agit de 10 voyelles isolées et de 8 consonnes prononcées
dans 3 contextes de voyelle symétrique (VCV), dont on extraira
l'image centrale.
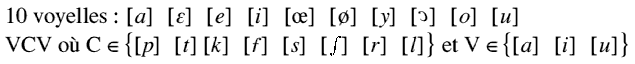
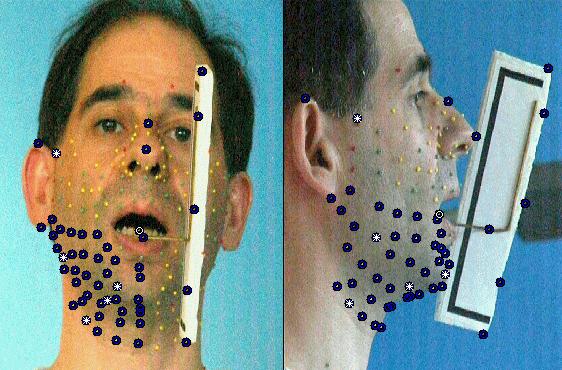
À ce stade du projet, la technique utilisée nécessite
que des marqueurs colorés (les petites billes qui apparaissent sur
l'image suivante) soient collées sur le visage, et matérialisent
donc les déformations du visage.
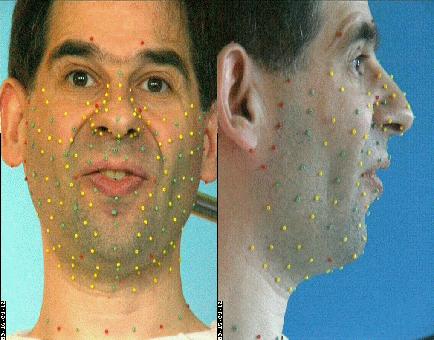
Plus de 180 billes tapissent le locuteur pour la phase de création du modèle articulatoire
Des positions des billes sur les images on déduira les positions (et
donc les mouvements) 3D grâce à l'utilisation de caméras
calibrées (au moins 2). On utilise pour la calibration un cube monté
sur un palet qui permet de le maintenir contre la mâchoire supérieure,
de sorte qu'en plus de permettre l'estimation des paramètres des
caméras, on définit (taille, position et orientation) un
repère privilégié rigidement lié à la
tête par sa mâchoire supérieure.
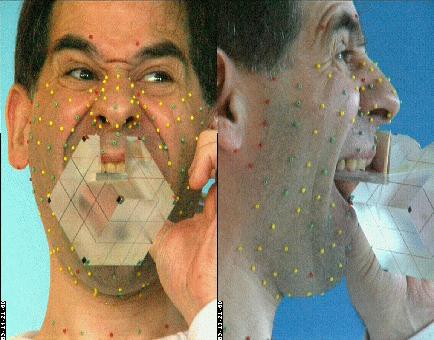
Le cube sert à calibrer les caméras et à définir un repère lié à la mâchoire supérieure
On aura aussi besoin d'inférer un modèle de déplacement
de la mâchoire inférieure, qui n'est généralement
pas directement visible. À l'aide du dispositif qui apparaît
sur la figure suivante (le 'jaw splint', sorte de fer à cheval qui
se cale sur les dents de la mâchoire inférieure et est rigide
avec une tige qui sort de la bouche et trahit donc les mouvements internes),
on rend ses déplacements mesurables pour toutes les configurations.
On peut alors enregistrer les coordonnées 3D de marqueurs externes
solidaires de la mâchoire inférieure, lors de l'articulation
d'un jeu de visèmes (plus restreint que le précédent).
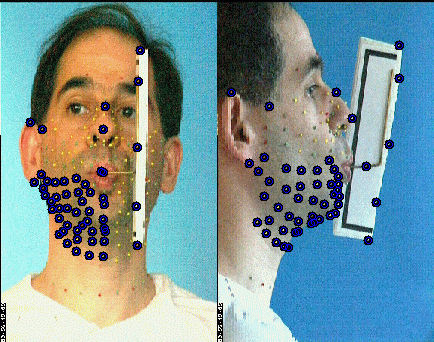
Les billes du dispositif reflètent la position et les mouvements de la mâchoire
À l'occasion de la collecte de ces données 3D qui sont
nécessaires à la construction du modèle articulatoire,
on enregistre aussi l'apparence visuelle du visage, sans billes,
qui servira à texturer le rendu graphique du modèle, pour
compléter le modèle articulatoire en un modèle pour
la synthèse graphique.
b/ Correction des mouvements de tête
Les coordonnées 3D des points vus dans chaque image doivent être
ramenées dans le repère commun lié au cube. Dans ce
but, et pour chaque image du corpus, on recherche (par optimisation non
linéaire, dans le logiciel Matlab) une combinaison rotation+translation
qui transforme les coordonnées de points relativement rigides entre
eux (près de la tempe, entre les deux yeux, sur les oreilles et
les dents supérieures) à celles de référence.
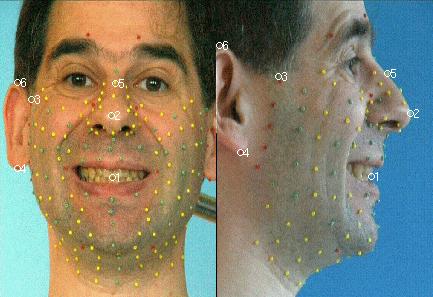
Les points 1,3, 4 et 5 sont suffisament rigides pour servir à réaligner la tête
c/ Etiquetage de points des lèvres
Pour chaque image du corpus articulatoire, on dispose de coordonnées
3D pour les points de chair qui sont matérialisés par
les billes. On va compléter ces mesures par des estimations de coordonnées
3D à la surface des lèvres et sur leurs contours. Pour cela,
on utilise un modèle de lèvres 3D, générique
et déformable qui a été construit à l'ICP.
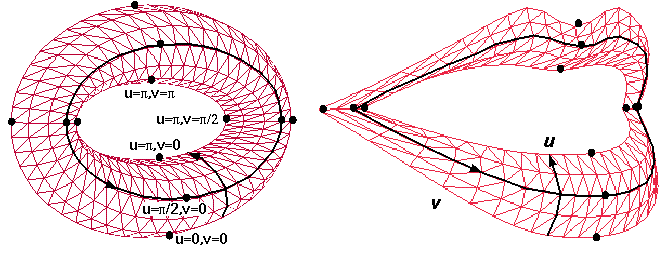
Le modèle 3D paramétrique de lèvres de l'ICP
C'est lui que l'on va adapter (manuellement) sur chaque visème,
jusqu'à ce que sa projection suivant le modèle de caméra
se conforme au contenu des images (qui sont des contraintes de face et
de profils). Comme il s'agit d'un modèle 3D, il sert à générer
des points 3D dont les coordonnées s'appliquent aux images de lèvres.
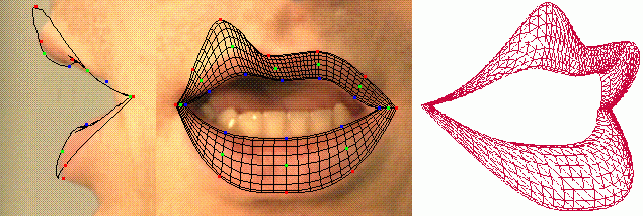
Déformable et adaptable, le modèle 3D de lèvres en cours de placement
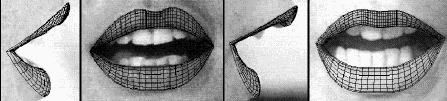
Le modèle 3D de lèvres appliqué à différentes postures/locuteurs
Ainsi, on dispose pour chaque visème de nouvelles coordonnées
3D qui viennent s'ajouter à celles des billes. Avant de générer
le modèle articulatoire, on va encore rajouter un point supplémentaire,
lié à la mâchoire inférieure.
d/ Prédiction du mouvement de mâchoire
Grâce à l'enregistrement du corpus jaw splint et après
correction des mouvements de la tête, on dispose de positions 3D
pour un point spécifique de la mâchoire inférieure
(dénommé LT, comme 'lower tooth', il est par exemple défini
à la jointure des deux incisives) et des points du visage. On cherche
à construire un modèle par régression linéaire,
qui d'après les coordonnées de quelques points du visage
prédise celles de LT. Le choix du modèle consiste à
tester les combinaisons de 3,4 ou 5 points du visage pour conserver celle
qui produit le minimum d'erreur de prédiction.
Le cercle blanc matérialise LT, et a été prédit
à partir des 5 billes réhaussées en blanc.
Une fois ce prédicteur construit, on peut l'appliquer, toujours
en parole naturelle, à chaque visème de l'autre corpus avec
billes pour obtenir des coordonnées 3D de LT, même quand il
n'est pas visible.
e/ Génération du modèle articulatoire
On dispose d'une collection (pour chaque visème) de déplacements
3D pour les points matérialisés par les billes, estimés
par le modèle de lèvres ou lié à la mâchoire
inférieure. Construire un modèle de ces mesures va consister
à définir un paramétrage qui les pilote. Le choix
s'est porté sur un modèle linéaire, tel qu'il pourrait
être créé par une analyse en composantes principales
(ACP). Cependant, et c'est une des spécificités de l'approche
de l'ICP, on lui préfère l'utilisation d'une ACP guidée
: connaissant les causes et conséquences de déformation du
visage, on va séquencer le calcul des sous-espaces propres selon
un ordre et des zones d'intérêt qui correspondent à
des manifestations visibles : on va successivement guider l'apparition
d'un mouvement lié aux déplacements de la mâchoire,
puis aux déformations des lèvres, et enfin au reste du visage.
Voici les détails de cette opération :
-
On retranche aux données leur moyenne arithmétique. Celle-ci
constituera la partie statique du modèle linéaire de prédiction.
-
De l'ACP des coordonnées 3D du point de mâchoire LT, on conserve
la première composante, qui devient notre premier prédicteur,
qu'on appellera 'jaw1'.
-
On effectuée sur les coordonnées résiduelles (sans
la moyenne, ni l'explication apportée par 'jaw1') des points des
lèvres une nouvelle ACP. Les deux premières composantes sont
isolées pour former deux prédicteurs, 'lip1' et 'lip2'.
-
Le quatrième prédicteur est constitué par 'jaw2',
seconde composante de l'analyse du mouvement de LT.
-
C'est 'lip3' qui sert de cinquième prédicteur.
-
Enfin, une dernière ACP du résidu (sans la moyenne ni les 5 prédicteurs) fournit, par sa composante
principale, le sixième prédicteur, 'face1'.
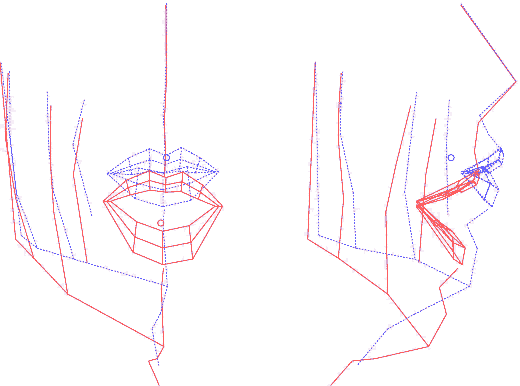
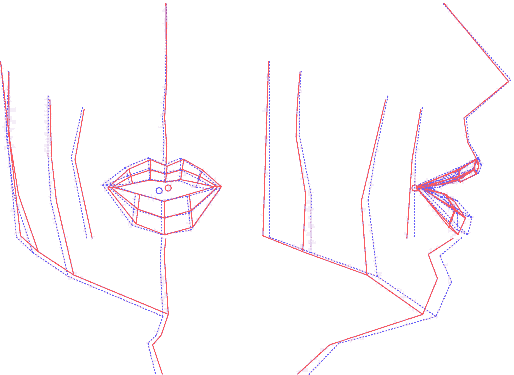
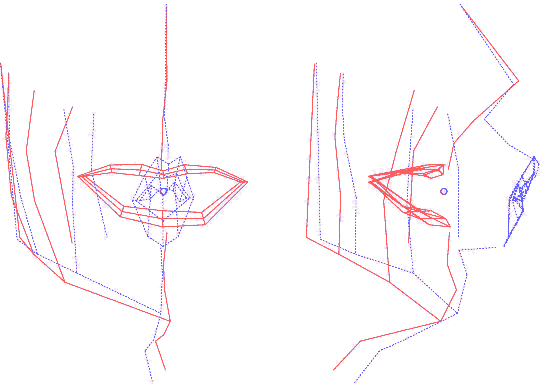
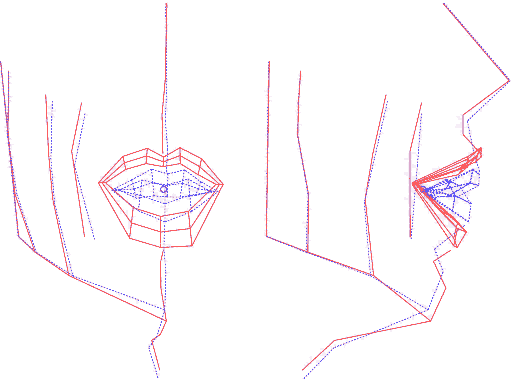
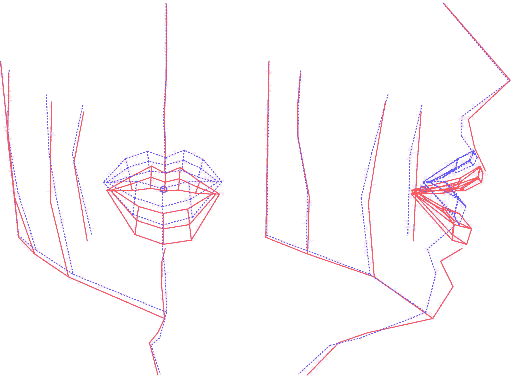
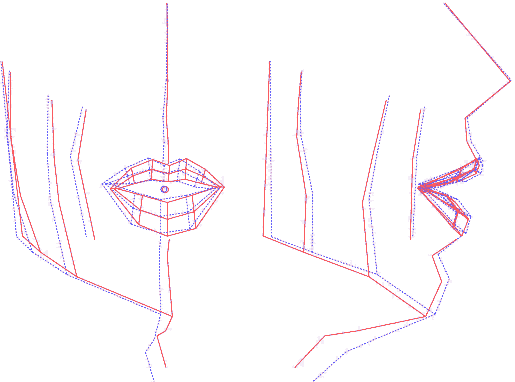
Ainsi construit, le modèle articulatoire permet de générer
les coordonnées 3D des points du visage et des lèvres, à
partir de la donnée de 6 paramètres, dont l'interprétation
est, par construction, articulatoire. En analysant les nomogrammes pour
chacun des paramètres, on peut retrouver ces mouvements dominants
: ouverture, protrusion et écartement des lèvres, ouverture
et avancée de la mâchoire et d'autres mouvements du visage
(menton et pomme d'Adam notamment).
Animation (AVI) montrant le mouvement de chaque composante
3/ Évaluation du modèle articulatoire
L'évaluation de la qualité des modèles construits
peut être faite à plusieurs niveaux :
-
en comparant, pour les données d'apprentissage ou pour de nouvelles
données de test, l'erreur de reconstruction entre les positions
réelles des billes sur les images et celles restituées après
projection sur le modèle articulatoire,
-
en mesurant l'évolution d'intelligibilité d'une séquence
audio-visuelle altérée : l'image est remplacée par
sa projection sur le modèle, et la piste son est plus ou moins dégradée.
À ce stade du rapport, on ne dispose que du modèle articulatoire,
pas encore d'un clone complet ; on ne peut donc examiner que les résultats
de couverture statistique. Voici les mesures obtenues en termes de variances
|
Variance à la reconstruction |
|
Explication |
Explication cumulée |
|
Jaw1 |
27.19 % |
27.19 % |
|
Jaw2 |
0.29 % |
27.48 % |
|
Lips1 |
60.23 % |
87.71 % |
|
Lips2 |
5.24 % |
92.95 % |
|
Lips3 |
3.00 % |
95.94 % |
|
Skin1 |
0.84 % |
96.78 % |