Analyse et synthèse de têtes parlantes
I/ Résumé du principe
II/ Le modèle articulatoire
III/ Modèle pour la synthèse
IV/ Techniques d'analyse
Effectuer l'analyse, c'est trouver pour les paramètres articulatoires
un jeu de valeurs tel qu'une image donnée du locuteur soit approchée
au mieux par le modèle de synthèse. Dans le cadre de Tempo
Valse, on se donne un modèle (articulatoire, de synthèse)
qui correspond au locuteur, et permet d'envisager d'effectuer une analyse,
sans maquillage, en situation de télécommunication.
À l'heure actuelle, trois méthodes différentes
ont été testées pour effectuer l'analyse dans le cadre
du labiophone :
-
analyse utilisant un traitement probabiliste chromatique de l'image caméra,
-
analyse utilisant un modèle texturé,
-
analyse utilisant un traitement probabiliste chromatique de l'image caméra
et du modèle texturé.
Toutes ces méthodes se basent sur le même schéma d'une
boucle d'analyse par synthèse. Avant de détailler les spécificités
des trois méthodes, on va rappeler le principe de ce paradigme.
1) Le paradigme de l'analyse par synthèse
a) Notion d'espace synthétisable
Comme on dispose d'un modèle de synthèse qui est paramétrable,
en faisant varier ces paramètres sur toutes les valeurs possibles,
on génère un espace d'images. Si le modèle était
complet, toutes les images réelles seraient synthétisables.
En pratique, ne serait-ce que du fait du faible nombre de paramètres,
comparé au nombre de pixels dans l'image, on ne peut que générer
une image approchée. Il faut donc quantifier en quoi ces images
se ressemblent plus ou moins, malgré leurs différences. À
ces notions de distance, on peut associer celle d'erreur de reconstruction.
b) Erreur de reconstruction
Puisqu'on ne pourra reconstruire qu'une image approchée, l'image
reconstruite qui sera jugée la plus proche peut varier fortement
selon le critère d'erreur choisi. Plus que la couleur ou l'aspect
de la peau (qui peuvent varier selon l'éclairage ou la pilosité),
on cherchera à construire des critères d'erreurs plus
invariants, à défaut d'être parfaits, et
qui s'intéressent
à la position comme à la forme des éléments du visage qui
convoient l'information d'intelligibilité.
c) Optimisation des paramètres du modèle
On cherche une configuration du modèle articulatoire qui reconstruise
au mieux l'image originale. En termes algorithmiques, cela revient à
trouver les paramètres d'articulation et de position qui minimisent
(si possible globalement, et à défaut localement) l'erreur
de reconstruction précédente. De nombreuses techniques existent
pour résoudre cette classe de problème, mais il faut cependant
noter qu'on aurait ici particulièrement intérêt à
minimiser le nombre de reconstructions et de calculs d'erreurs (c'est à
dire le nombre d'itérations de l'algorithme d'optimisation) car
ces étapes sont très coûteuses, du fait de la taille
des images manipulées.
Dans les réalisations qui suivent, une approche dichotomique
d'exploration de l'espace des paramètres (articulatoires et de position)
a été utilisée. Elle pénalise bien sûr
le temps d'exécution, mais il est prévu, pendant le déroulement
du projet, de tester d'autres stratégies et algorithmes d'optimisation,
et notamment celui du Simplexe.
2) Analyse/synthèse de lèvres avec modèle chromatique
Comme les lèvres sont un élément clé de la
parole visible, on peut souhaiter qu'elles constituent l'ancrage privilégié
pour la synthèse du modèle. Il est alors naturel de chercher
une erreur qui se focalise sur la position reconstruite des lèvres,
et l'adéquation de sa forme avec celle estimée sur l'image
caméra.
Cette première méthode d'analyse consiste à se
concentrer sur la légère différence chromatique entre
la peau et les lèvres de chaque image en provenance de la caméra.
Chaque pixel vidéo se voit affecté d'une probabilité
d'être un point de lèvres, et pourra moduler positivement
(ou négativement) le critère d'erreur de reconstruction s'il
est couvert par une partie lèvres (ou respectivement, par une partie
peau) du modèle articulatoire projeté.
a) Modèle statistique discriminant
On considère qu'existent deux classes, suffisamment séparables,
qui recouvrent les points des lèvres (classe 'vermillon') et les
autres points du visage (notamment la peau autour des lèvres).
Actuellement, ces deux classes sont initialisées en spécifiant
à la souris des zones disjointes qui les représentent. Si l'on note 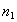 le nombre de pixels du vermillon, et
le nombre de pixels du vermillon, et 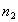 le nombre de pixels de l'autre classe, on peut construire le vecteur discriminant :
le nombre de pixels de l'autre classe, on peut construire le vecteur discriminant :
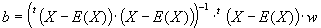
où
On peut alors définir une probabilité qu'un pixel appartienne à la classe vermillon :
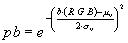
avec 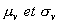 la moyenne et l'écart type de
la moyenne et l'écart type de 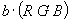 pour les pixels vermillon de l'apprentissage.
pour les pixels vermillon de l'apprentissage.
b) Erreur de reconstruction
Le modèle articulatoire recouvre la zone des lèvres et une
bande de peau autour d'elles. Lorsqu'on projette le modèle sur une
image caméra, on souhaite obtenir un score qui soit d'autant meilleur
qu'il y a adéquation entre la prédiction (projection de ces
zones) et la réalisation (probabilité calculée pour
chaque pixel).
"image lèvres+bande de peau"
L'erreur de reconstruction qui a été utilisée est
:

c) Résultats obtenus
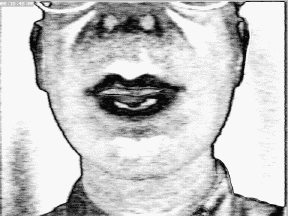
Image de probabilités lèvres/peau
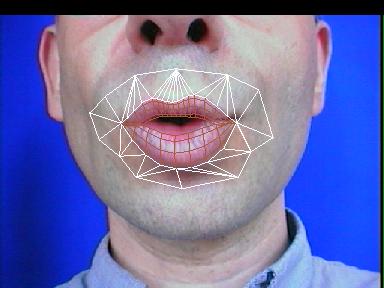
Le modèle local trouvé par l'analyse, superposé à son image cible
3) Analyse/synthèse de modèles texturés
La méthode précédente, en privilégiant les
lèvres dans le critère d'erreur, en fait une cible privilégiée.
Ainsi, sans avoir pourtant exprimé une contrainte explicite sur
les contours, ceux-ci sont généralement atteints par le modèle
déformable.
Dans un cas plus général, on souhaite utiliser un modèle
de visage plus vaste que celui du proche voisinage des lèvres :
dès lors, il semble raisonnable de penser que le prétraitement
statistique, en plus de rehausser le contraste lèvre/peau,
va aussi affaiblir ou masquer des informations de couleur ou de texture
qui étaient sur l'image caméra : un grain de beauté,
ou une ride de parole, sont pourtant des éléments dont on
voudrait qu'ils servent d'ancres pour l'analyse, sans avoir à exprimer
a priori qu'ils sont présents sur l'image (comme pour les lèvres)
si l'on veut que la procédure puisse être répétée
sur d'autres locuteurs.
La solution à ce problème passe probablement par l'utilisation
de la texture (des textures) du modèle, qui inclut les éléments
spécifiques au locuteur. Deux expériences ont déjà
été réalisées pour évoluer vers une
solution plus satisfaisante :
-
Chaque pixel (texturé) projeté depuis le modèle est
comparé avec le pixel de l'image caméra qu'il recouvre. L'erreur
constituée par la somme des carrés des différences
pixel-à-pixel renseigne sur un alignement global 'parfait'. En pratique,
cette approche marche au mieux avec des images du corpus de définition,
mais s'avère sinon trop sensible aux variations d'éclairage
(même en normalisant les images ou les zones traitées) ou
de pilosité faciale : elle ne dégage pas d'information invariante,
puisqu'on exploite directement les données brutes, RGB.
-
On fait subir aux textures du modèle un prétraitement chromatique
analogue à celui de la première méthode d'analyse/synthèse,
et on utilise une erreur pixel-à-pixel pour mesurer l'adéquation
de chaque reprojection. Ainsi, au lieu de mettre en correspondance des
pixels RGB, on mettra en correspondance des mesures de probabilité
(d'être des points vermillon ou pas), comme cela a été fait pour la figure qui suit. On a donc autant de chance
de capturer (sans les expliciter) les contours des lèvres qu'avec
la première méthode, mais on peut espérer capturer
d'autres détails. Dans une prochaine expérience, on essaiera
de complémenter ce plan peau/lèvres par d'autres plans discriminants
(peau/non peau et pilosité/non-pilosité). Jusqu'à
concurrence de 3 critères par texture, le coût devrait rester
proche de celui avec une texture RGB (3 plans) dans les implémentations
à base de carte 3D accélératrice.
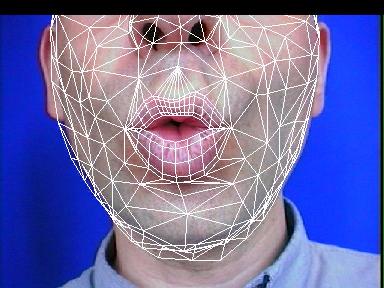
Un modèle mis en correspondance par la dernière méthode
3/ Résultats de l'analyse
Avec une texture et une procédure d'analyse, il devient possible de comparer, pour les images du corpus
d'apprentissage, l'image reconstruite avec l'image originale. Une image de
différence visualise les zones où une erreur,
systématique ou résiduelle,
apparaîtrait. On mesure ainsi l'apport, ne serait-ce que pour la
synthèse, des textures multiples (notamment pour le pli joue/bouche).
"image de diff. du i"
Dans le cas d'images caméras quelconques, cette comparaison
n'est pas exploitable, du fait des différences précédemment
évoquées (lumière...). On peut par contre avoir recours
aux tests d'intelligibilité introduits plus tôt dans ce rapport
pour quantifier la qualité des reconstructions fournies par la synthèse
après analyse/synthèse d'une séquence audio-visuelle.
a/ Résultats des tests d'intelligibilité
L'un des tous premiers modèles construits ne comportait qu'un demi-visage
(avec les lèvres complètes, mais maquillées en bleu
à l'époque) et où la seule texture disponible inclut
les billes. Pour ce modèle, on dispose déjà des résultats
de mesures d'intelligibilité.
"tableau des résultats d'intelligibilité"
Pour les nouveaux modèles construits (visage complet, texture
sans bille), le même protocole de test va bientôt être
appliqué, et l'on disposera alors de résultats similaires
(mais qu'on peut raisonnablement espérer meilleurs).
Une séquence vidéo présente un message audio-visuel (2Mo), resynthétisé après analyse :
V/ Génération et interprétation de FAPs MPEG-4
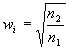 si l'échantillon i appartient à la classe vermillon,
si l'échantillon i appartient à la classe vermillon, 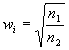 sinon.
sinon.