Démarche générale
Mon approche consiste à étudier la parole comme un phénomène multimodal et incarné, à travers la démarche suivante :
- mettre en place des dispositifs expérimentaux permettant d'acquérir des signaux acoustiques, articulatoires, visuels et physiologiques ;
- développer des modèles d'apprentissage automatique capables de relier ces signaux à des représentations linguistiques, motrices ou perceptives ;
- intégrer ces modèles dans des systèmes interactifs, tels que des technologies d'assistance à la communication parlée ou des robots humanoïdes, qui s'insèrent dans les boucles sensori-motrices régulant la communication humaine.
Les applications de mes travaux concernent :
- le développement de technologies vocales destinées aux personnes présentant des troubles de la communication parlée ;
- l'amélioration des capacités socio-communicatives des robots ;
- l'étude, par la modélisation et la simulation, des mécanismes cognitifs impliqués dans l'acquisition du langage et de la parole.
Modélisation computationnelle des mécanismes de perception, de production et d'acquisition de la parole
Objectifs
- Explorer comment les interactions sensori-motrices, physiques et sociales façonnent l'apprentissage du langage et de la parole.
- Comprendre comment tirer parti de ces interactions pour améliorer l'efficacité et l'adaptabilité des IA conversationnelles.
Résultats
- Développement d'un modèle computationnel neuronal d'imitation vocale permettant l'apprentissage auto-supervisé des relations sensori-motrices de la parole, notamment des relations acoustico-articulatoires.
- Mise en évidence du rôle de l'inférence motrice dans la découverte d'unités phonétiques.
- Mise en évidence du rôle de représentations acoustiques invariantes dans l'apprentissage articulatoire.
- Étude de biais phonétiques universels pour l'apprentissage d'unités acoustiques en faible quantité de données.

Modèle d'imitation vocale auto-supervisée : apprendre les relations entre perception, gestes articulatoires et production de parole.
Publications
- Hueber T., Tatulli E., Girin L., Schwartz J.-L. (2020), Evaluating the potential gain of auditory and audiovisual speech predictive coding using deep learning, Neural Computation, vol. 32, n° 3, pp. 596-625.
- Georges M.-A., Lavechin M., Schwartz J.-L., Hueber T. (2024), Decode, Move and Speak! Self-supervised Learning of Speech Units, Gestures, and Sound Relationships Using Vocal Imitation, Computational Linguistics, vol. 50, n° 4, pp. 1345-1373.
- Lavechin M., Hueber T. (2025), From perception to production: how acoustic invariance facilitates articulatory learning in a self-supervised vocal imitation model, EMNLP, pp. 23852-23863.
- Ortiz A., Khentout M., Benchekroun Y., Hueber T., Dupoux E. (2026), MauBERT: Universal Phonetic Inductive Biases for Few-Shot Acoustic Units Discovery, ACL.
Contexte : chaire DevAI&Speech (MIAI Cluster), chaire Bayesian Cognition and Machine Learning for Speech Communication (MIAI), ERC Speech Unit(e)s, post-doctorat de Marvin Lavechin, thèse de Marc-Antoine Georges, thèse d'Angelo Ortiz.
Apprentissage de représentations de la parole
Objectifs
- Apprendre, de manière auto-supervisée ou faiblement supervisée, des représentations riches, interprétables et contrôlables de la parole et des signaux audio.
- Exploiter ces représentations pour le rehaussement et la restauration de la parole pathologique.
Résultats
- Formulation théorique d'une nouvelle classe de modèles auto-supervisés : les auto-encodeurs variationnels dynamiques (DVAE).
- Régularisation d'espaces latents de VAE afin de permettre le contrôle interprétable du timbre musical, en collaboration avec Arturia.
- Développement de méthodes de restauration de segments de parole manquants par speech inpainting.

Architecture de speech inpainting : transférer des représentations SSL vers la reconstruction de segments de parole masqués.
Publications
- Asaad I., Jacquelin M., Perrotin O., Girin L., Hueber T. (2026), Is Self-Supervised Learning Enough to Fill in the Gap? A Study on Speech Inpainting, Computer Speech & Language.
- Girin L., Leglaive S., Bie X., Diard J., Hueber T., Alameda-Pineda X. (2021), Dynamical Variational Autoencoders: A Comprehensive Review, Foundations and Trends in Machine Learning.
- Roche F., Hueber T., Garnier M., Limier S., Girin L. (2021), Make That Sound More Metallic: Towards a Perceptually Relevant Control of the Timbre of Synthesizer Sounds Using a Variational Autoencoder, Transactions of the International Society for Music Information Retrieval.
Contexte : thèse de Fanny Roche, collaboration Arturia, thèse de Marc-Antoine Georges, collaboration INRIA RobotLearn et LPNC.
Silent speech interface
Objectifs
- Convertir une parole articulée mais non vocalisée en texte ou en signal acoustique intelligible.
- Comprendre et modéliser le contrôle de la prosodie en parole silencieuse.
Résultats
- Première interface de communication en parole silencieuse basée sur l'acquisition de données articulatoires combinant échographie linguale et vidéo.

Interface de parole silencieuse : acquisition articulatoire multimodale et conversion vers la parole audible.
Publications
- Tatulli E., Hueber T. (2017), Feature extraction using multimodal convolutional neural networks for visual speech recognition, IEEE ICASSP, pp. 2971-2975.
- Hueber T., Bailly G. (2016), Statistical Conversion of Silent Articulation into Audible Speech using Full-Covariance HMM, Computer Speech & Language.
- Hueber T. et al. (2010), Development of a Silent Speech Interface Driven by Ultrasound and Optical Images of the Tongue and Lips, Speech Communication.
Contexte : ma thèse et post-doctorat d'Eric Tatulli.
Traitement automatique des langues gestuelles
Objectifs
- Reconnaître et automatiser la Langue française Parlée Complétée (LPC).
- Synthétiser la LPC à partir de texte.
- Analyser la coordination temporelle entre les mouvements de la main et les mouvements labiaux en LPC.
- Traduire automatiquement la Langue des Signes Française (LSF) en texte.
Résultats
- Premier système complet de décodage et de synthèse de la Langue française Parlée Complétée (LfPC) basé sur un pipeline entièrement neuronal.
- Corpus Mediapi-RGB pour l'entraînement de modèles de traduction automatique de LSF.

Reconnaissance automatique de la Langue française Parlée Complétée : combiner informations labiales, manuelles et linguistiques.
Publications
- Sankar S., Lenglet M., Bailly G., Beautemps D., Hueber T. (2025), Cued Speech Generation Leveraging a Pre-trained Audiovisual Text-to-Speech Model, ICASSP.
- Sankar S., Beautemps D., Elisei F., Perrotin O., Hueber T. (2023), Investigating the dynamics of hand and lips in French Cued Speech using attention mechanisms and CTC-based decoding, Interspeech.
Contexte : projet H2020 Comm4Child, thèse de Sanjana Sankar.
Synthèse vocale incrémentale
Objectifs
- Réduire la latence des systèmes de synthèse vocale à partir du texte.
- Produire une parole naturelle avant que la phrase complète soit disponible.
Résultats
- Quantification de l'impact du contexte futur sur la qualité prosodique du TTS neuronal.
- Amélioration de la prosodie avec des prédictions de texte futur.
- Fine-tuning d'un modèle GPT permettant de prédire en ligne la présence d'un focus contrastif sur un mot au cours de la saisie.

Synthèse vocale incrémentale : réduire la latence dans une interaction assistée par synthèse de parole.
Publications
- Stephenson B., Besacier L., Girin L., Hueber T. (2022), BERT, can HE predict contrastive focus?, Interspeech.
- Stephenson B., Hueber T., Girin L., Besacier L. (2021), Alternate Endings: Improving Prosody for Incremental Neural TTS with Predicted Future Text Input, Interspeech.
- Stephenson B., Besacier L., Girin L., Hueber T. (2020), What the Future Brings: Investigating the Impact of Lookahead for Incremental Neural TTS, Interspeech.
- Pouget M., Hueber T., Bailly G., Baumann T. (2015), HMM Training Strategy for Incremental Speech Synthesis, Interspeech.
Biofeedback articulatoire pour la rééducation orthophonique
Objectifs
- Rendre visibles les gestes articulatoires pour accompagner la rééducation orthophonique.
- Évaluer l'apport de l'échographie linguale et de modèles articulatoires en situation clinique.
- Développer des systèmes capables de prédire en temps réel les mouvements articulatoires directement à partir du signal de parole.
Résultats
- Protocoles de rééducation après glossectomie utilisant l'illustration échographique et le feedback visuel.
- Apport de l'illustration visuelle des articulateurs pour la rééducation des troubles de la parole post-AVC.
- Algorithme C-GMR pour l'adaptation à un nouveau locuteur d'une régression par modèle de mélange gaussien.
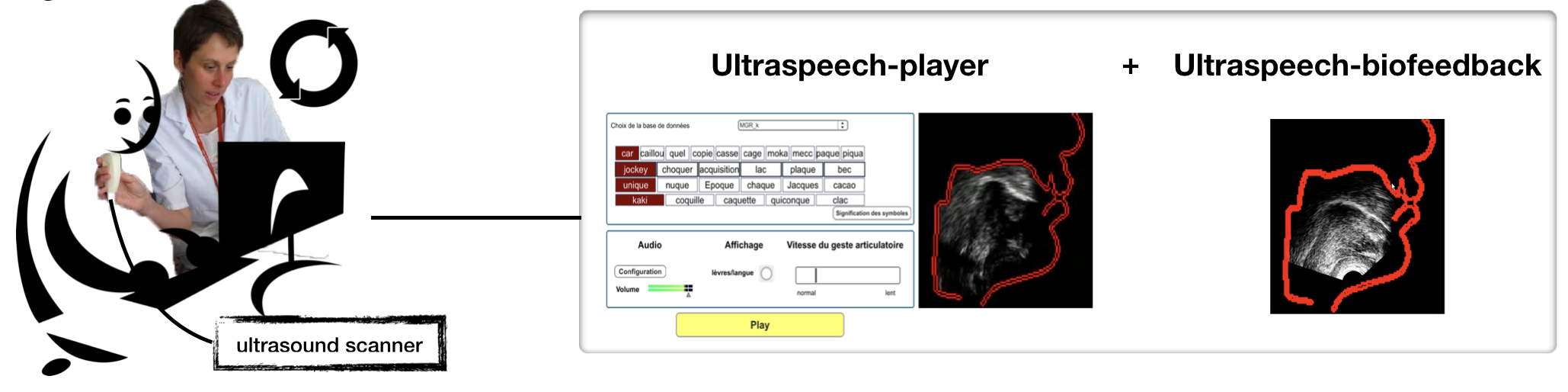
Biofeedback articulatoire : rendre visibles les mouvements de la langue pour accompagner la rééducation.
Publications
- Hueber T., Girin L., Alameda-Pineda X., Bailly G. (2015), Speaker-Adaptive Acoustic-Articulatory Inversion using Cascaded Gaussian Mixture Regression, IEEE/ACM TASLP.
- Girod-Roux M. et al. (2020), Rehabilitation of speech disorders following glossectomy, based on ultrasound visual illustration and feedback, Clinical Linguistics & Phonetics.
- Fabre D., Hueber T., Girin L., Alameda-Pineda X., Badin P. (2017), Automatic animation of an articulatory tongue model from ultrasound images of the vocal tract, Speech Communication.
- Haldin C. et al. (2018), Speech rehabilitation in post-stroke aphasia using visual illustration of speech articulators: A case report study, Clinical Linguistics & Phonetics.
Contexte : thèse de Diandra Fabre, stage de Master de Marion Girod-Roux, projet Revison, projet Vizart3D, collaborations DDL Lyon, CHU Lyon, centre médical Rocheplane, LPNC et INRIA RobotLearn.
Interfaces cerveau-machine pour la parole
Objectifs
- Explorer la restauration de la communication parlée à partir de signaux cérébraux intra-crâniens (ECoG) liés à la production de parole.
Résultats
- Identification des contraintes méthodologiques clés pour concevoir une BCI de parole.
- Première démonstration d'un système de conversion acoustico-articulatoire en temps réel, adaptable au locuteur, basé sur l'articulographie électromagnétique.
Publications
- Bocquelet F., Hueber T., Girin L., Chabadès S., Yvert B. (2017), Key considerations in designing a speech brain-computer interface, Journal of Physiology-Paris.
- Bocquelet F., Hueber T., Girin L., Savariaux C., Yvert B. (2016), Real-Time Control of an Articulatory-Based Speech Synthesizer for Brain Computer Interfaces, PLOS Computational Biology.
Contexte : projets ANR BrainSpeak et H2020-FETPROACT BrainCom, en collaboration avec l'INSERM, thèse de Florent Bocquelet.
Pour la liste complète et maintenue automatiquement, voir la page Publications. Les logiciels et démonstrateurs disponibles sont regroupés sur la page Logiciels.
Grenoble Images Parole Signal Automatique laboratoire
UMR 5216 CNRS - Grenoble INP - Université Grenoble Alpes