Analyse et synthèse de têtes parlantes
I/ Résumé du principe
II/ Le modèle articulatoire
III/ Modèle pour la synthèse
IV/ Techniques d'analyse
V/ Génération et interprétation de FAPs MPEG-4
1) Quelques éléments du standard
Dans le cadre du codage objet d'éléments de scènes audiovisuelles, le standard MPEG-4 prévoit la compression
de visages animés ou parlants par le biais d'un noeud spécifique du graphe de scène, le noeud FACE. Ce dernier permet
de spécifier un visage, aussi bien dans son apparence que pour son animation, par exemple synchronisée avec un
synthétiseur vocal opérant d'après des données textuelles.
a) Adaptation au locuteur
Le norme MPEG-4 prévoit, pour les implémentations haut-niveau,
de pouvoir adapter le modèle présent dans le terminal selon
diverses caractéristiques envoyées par le serveur :
- données anthropomorphiques (espacement/positions de divers points caractéristiques du visage),
- modèle surfacique du visage (mesh 3D générique),
- texture à appliquer,
- modèle d'animation du visage.
Pour le profil minimal 'simple face', ces extensions ne sont pas
exigées, et l'on reste donc dans la norme en ne les implémentant
pas immédiatement. Le décodeur proposé par l'ICP va
donc dans un premier temps mettre de coté cette extension à la visualisation multi-représentations,
et s'intéresser aux problèmes liés à l'animation réaliste pour la labiophonie :
- le codage des mouvements articulatoires inversés d'après la micro-caméra et le modèle articulatoire : pour transcrire
les paramètres articulatoires "propriétaires" en un codage par FAP compatible MPEG-4,
- l'application au modèle articulatoire embarqué sur le décodeur des flux de FAP reçus,
ce qui réalise le multi-locuteurs, mais sans changement de l'apparence statique du clone visualisé par le décodeur.
Du point de vue du graphe de scène, cela conduit à s'intéresser aux noeuds FACE et FAP, sans les noeuds FDP.
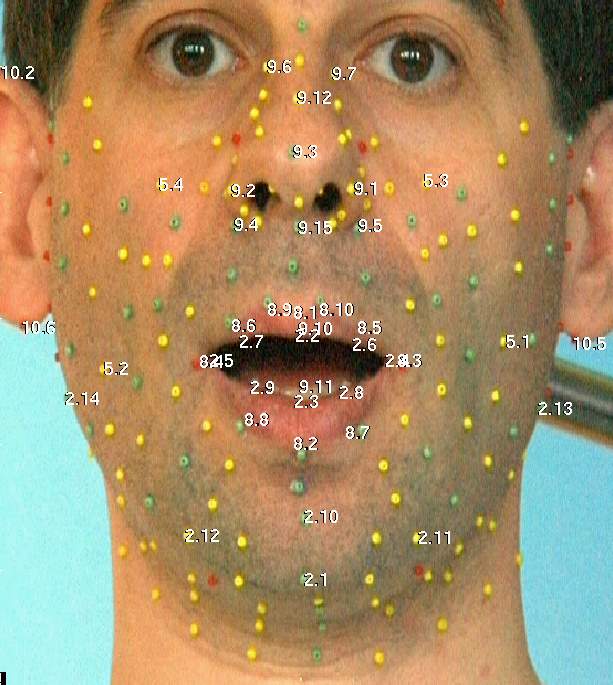
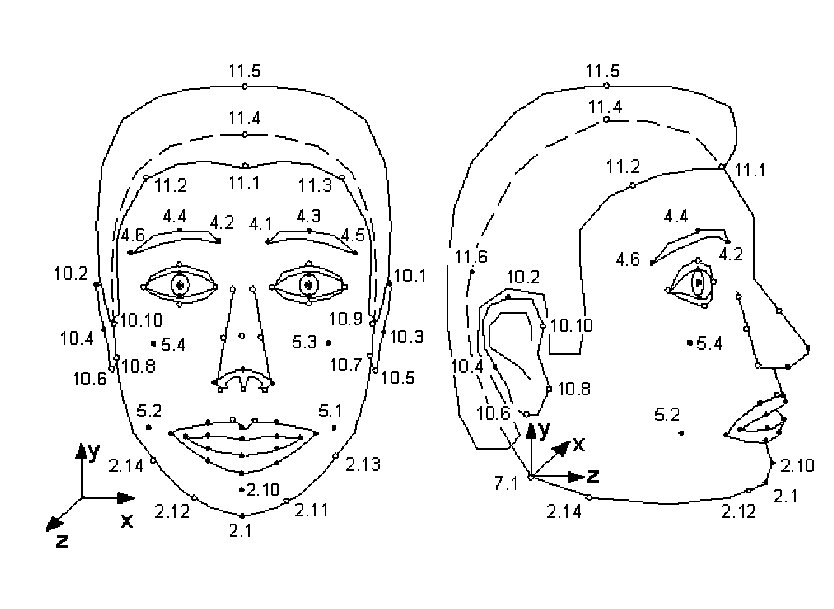
b) Feature points
MPEG-4 définit un certain nombre de points caractéristiques
sur le visage, rassemblés en groupes.
 |
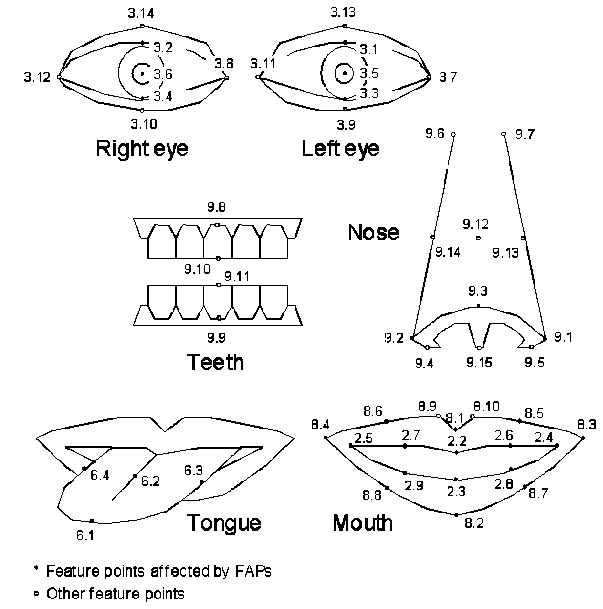 |
Les points caractéristiques de MPEG-4 FACE
En plus de permettre de conformer le modèle présent dans le décodeur
(pour personnaliser l'affichage), un sous-ensemble de ces points MPEG-4 est directement addressable pour piloter l'animation.
En interne, le décodeur peut bien sûr
avoir plus de points sur son maillage, et il lui incombe de tous les déplacer
de façon cohérente. Rappelons que la norme ne statue pas
sur l'apparence, ni même l'obligation de résultat, seulement sur les formats
qui transitent et une partie de leur interprétation.
c) Position neutre et FAPU
MPEG-4 spécifie aussi une position neutre du clone, à partir
de laquelle seront encodés les déplacements de certains points
caractéristiques, pour l'animation du clone.
Cette position est aussi celle qui sert à définir les 6 unités de mesure (FAPU, Face animation parameter units) :
la largeur de la bouche au repos, la distance nez/bouche, l'écartement des deux yeux,
le diamètre de l'iris, la hauteur entre les yeux et la base du nez ainsi qu'une unité d'angles.
Selon le mouvement local à exprimer, par exemple pour les commissures, le menton ou les paupières, la norme
spécifie laquelle de ces unités sert d'échelle de mesure. Par ce biais, les mouvements codés héritent d'une certaine indépendance vis-à-vis du locuteur (facilitant le passage du
locuteur original distant à celui représenté sur le terminal) et pourront être quantifiés avec des pas différents.
d) Codage FAP
Pour coder les mouvements du visage dus à l'articulation, MPEG-4 propose le principe des FAP (Face Animation Parameters).
Chaque FAP décrit le mouvement dans une seule direction (en X, en Y ou parfois en rotation)
d'un sous-ensemble de ces points (il y a donc parfois plusieurs FAP associés à un même point, tandis que certains Features Points ne sont pas
explicitement pilotable).
Ramené dans l'unité que spécifie la norme, leur déplacement depuis la position de repos fournit la base de la valeur du FAP considéré (pour l'encodage du flux,
quantisation et prédictions sont à ajouter).
La norme ne spécifie pas les algorithmes qui permettent de trouver les valeurs des FAP pour encoder la vidéo d'un visage parlant.
Pas plus qu'elle ne spécifie la façon d'appliquer les FAP au modèle animé du décodeur, dont on ne doit pas supposer qu'il est
le même que celui utilisé à l'encodage. Ces problèmes sont délicats, et constituent surement l'un des freins technologiques
actuels au développement de MPEG-4 SNHC/FACE.
Dans la suite de ce document, on va voir en quoi l'utilisation -- invisible du point de vue des flux MPEG-4 échangés, et donc compatible -- d'un modèle articulatoire de l'ICP, permet de résoudre ces
difficultés, dans le cadre de la labiophonie du terminal TempoValse.
2) Encodage de FAP à l'aide d'un modèle articulatoire
a) Données embarquées dans le terminal
Pour l'analyse, le terminal intègre un modèle
articulatoire, par exemple celui de Pierre Badin. En tant qu'encodeur MPEG-4, il
doit en plus posséder la correspondance avec un minimum de points caractéristiques (selon qu'on s'intéresse
à la parole, aux expressions...).
La figure suivante montre un certain nombre de points étiquetés
sur deux de nos modèles.
Ces points MPEG-4 correspondent exactement à des points du modèle :
ce sont soit directement des billes de l'enregistrement, soit des points du modèle 3D
de lèvres, ou éventuellement des combinaisons linéaires
de ces derniers. Quitte à avoir éventuellement enrichi le modèle linéaire de quelques nouveaux points, on disposera donc
de tous les points MPEG-4 jugés nécessaires (pour la parole, voire les expressions).
L'encodeur doit aussi connaître la position neutre (soit les positions 3D, soit les paramètres correspondants du modèle).
Comme la procédure de construction du modèle produit des tailles réelles (par exemple, en mètres), il a donc aussi
accès aux unités nécessaires à l'encodage.
b) Calcul des FAP
L'analyse (utilisant le modèle articulatoire) fournit donc des coordonnées 3D pour tous les points du modèle, et notament ceux qui
sont directement liés aux FAP du standard. D'après leurs déplacements depuis les positions de repos, mis à l'échelle selon l'unité ad hoc,
l'encodage proprement dit consistera en une quantification, différente pour les trames intra et celles prédites
de la précedente,. Il y aura aussi transmission d'un masque de bits pour spécifier les FAP qui sont effectivement transmis (on peut donc exclure ceux
liés aux expressions et que nous n'inversons pas avec notre modèle).
Il n'y a donc pas de difficulté particulière pour la génération des valeurs de FAP, dès lors que le tracking a pu être effectué. Par contre, l'utilisation
d'un modèle pour le tracking permet d'avoir des valeurs a priori moins bruitées pour les nombreux points MPEG-4, particulièrement dans le tracking
sans marqueur : le modèle a priori est garant d'une certaine cohérence entre tous les points du visage (alors que MPEG-4 permet une décohérence qui
dépasse la carricature) et permet de générer des mouvements fins et non-localisés à partir d'un tracking réduit. Par contre, les expressions sont a priori
tronquées, dans le mode labiophone (dont le but reste l'intelligibilité et le faible débit) du terminal.
3) Décodage de FAP à l'aide d'un modèle articulatoire
De façon symétrique à ce qui s'est passé à l'encodage, on reçoit un flux de FAP (avec un masque de bits), c'est à dire que tous les FAP ne sont pas
forcément renseignés. La norme prévoit un mécanisme de généralisation : par exemple, par symétrisation, les mouvements de points gauches non spécifiés ont
été copiés des FAP des points de droite. Pour ce faire, le décodeur peut avoir reçu un graphe, qui spécifie les dépendances et la façon de calculer certains des
FAP non spécifiés. Le décodeur peut aussi inclure et exécuter certaines règles par défaut.
On supposera par la suite que tous ces mécanismes ont bien été appliqués par le décodeur de FAP, mais sans présumer
que tous les FAP se retrouvent forcément affectés.
Le problème qui se pose est celui de la transposition vers le modèle qui est embarqué dans le terminal (vu ici comme un décodeur).
a) Données embarquées dans le décodeur
Elles sont de même nature que celles utiles au codeur, mais ne représentent bien sûr pas forcément le même visage (visuellement et articulatoirement).
b) Inversion des FAP
À partir des FAP, en additionnant la position neutre et en revenant aux tailles réelles (par application de l'unité ad hoc tirée du modèle
du recepteur), on génère une liste de positions (X, Y et/ou Z selon le FAP) d'un sous-ensemble de Feature Points. Un certain nombre de ceux-ci
sont effectivement pilotés par notre modèle articulatoire, et constituent donc les cibles à atteindre.
Pour trouver les valeurs de paramètres articulatoires du modèle qui réalisent au mieux le mouvement
spécifié, et comme le modèle est linéaire, un simple moindre carré est suffisant (on peut cependant borner les paramètres par exemple entre -4 et 4).
Comme le système à résoudre dépend du nombre de FAP effectivement reçus, il ne peut pas être inversé a priori. On peut par contre optimiser le cas, probablement
courant, où le même sous-ensemble de FAP (par exemple, tous), sont reçus à chaque trame.
Ainsi, dans le cas du modèle de Pierre, à partir d'au moins 6 FAP "parole" mis en correspondance, on va récuperer 6 valeurs pour nos paramètres articulatoires. En les appliquant
au modèle de synthèse, on réalise donc un décodage du flux de FAP reçu.
Ce décodage correspondra exactement à l'encodage si l'encodeur a utilisé le même modèle (aux quantisations et écrêtages près). Dans le
cas de FAP liés à une activité parole, le décodage est censé être cohérent, mais ne reproduira pas parfaitement l'articulation du locuteur distant. Dans le cas d'expressions,
celles-ci ne seront que partiellement décodées (sourires) ou disparaîtront (froncement de sourcils...).
On est donc bien dans le cadre du décodage de labiophonie : sans changer l'apparence visuelle du clone décodé, on fournit les indices visuels liés à la parole
et censés augmenter l'intelligibilité, comme l'arrondissement et le contact des lèvres. Implicitement, une paire codeur-décodeur réalise un codage sémantique du message audiovisuel original,
à un coût compatible à la fois avec un faible débit réseau et un raffraîchissement élevé à l'écran.
4) Résultats
Toutes les séquences trackées sur Pierre ("la bise et le soleil", "les deux camions"...) ont été transcrites en FAP. La reconstruction après décodage FAP
sur le modèle original fait apparaître quelques pertes du signal, même sans quantisation, du fait de l'écrêtage : il est possible de modifier
la position neutre pour minimiser cet effet, mais il faut rester compatible avec la sémantique, pas très précise, imposée par MPEG-4.
La reconstruction sur un autre modèle construit récemment à l'ICP, d'après un locuteur en langue arabe, a aussi été testée. Reciproquement, des séquences
en arabe issues de ce second locuteur ont été transposées sur le modèle issu de Pierre.
L'encodage FAP de séquences TTS(.avi, 10Mb) a aussi été testé.