My research activities focus on automatic speech processing, with a particular interest in the capture, analysis and modeling of articulatory gestures and electrophysiological signals involved in its production. My work is divided into two axes: (1) the development of speech technologies that exploit these different signals, for speech recognition and synthesis, for people with a spoken communication disorder, and (2) the study, through modeling and simulation, of the cognitive mechanisms underlying speech perception and production, and in particular the self-supervised learning of sensory-motor representations.
Axis 1: Assistive speech technology
Silent Speech Interfaces
![]() Tatulli,
E., Hueber, T.,, "Feature
extraction using multimodal convolutional neural networks for
visual speech recognition", Proceedings of IEEE ICASSP, New
Orleans, 2017, pp. 2971-2975.
Tatulli,
E., Hueber, T.,, "Feature
extraction using multimodal convolutional neural networks for
visual speech recognition", Proceedings of IEEE ICASSP, New
Orleans, 2017, pp. 2971-2975.
![]() Hueber,
T., Bailly, G. (2016), Statistical
Conversion of Silent Articulation into Audible Speech using
Full-Covariance HMM, Computer Speech and Language, vol. 36,
pp. 274-293 (preprint
pdf).
Hueber,
T., Bailly, G. (2016), Statistical
Conversion of Silent Articulation into Audible Speech using
Full-Covariance HMM, Computer Speech and Language, vol. 36,
pp. 274-293 (preprint
pdf).
![]() Bocquelet
F, Hueber T, Girin L, Savariaux C, Yvert B (2016)
Real-Time Control of an Articulatory-Based Speech Synthesizer
for Brain Computer Interfaces. PLOS Computational Biology
12(11): e1005119. doi: 10.1371/journal.pcbi.1005119
Bocquelet
F, Hueber T, Girin L, Savariaux C, Yvert B (2016)
Real-Time Control of an Articulatory-Based Speech Synthesizer
for Brain Computer Interfaces. PLOS Computational Biology
12(11): e1005119. doi: 10.1371/journal.pcbi.1005119
Incremental Text-to-Speech Synthesis
Text-to-Speech (TTS) systems are now of sufficient quality to be deployed in general purpose applications and to be used by people who have lost the use of their voice. However, a classical TTS synthesizer works at the sentence level: text analysis and sound synthesis are triggered each time the user has finished typing a complete sentence. The knowledge of the beginning and end boundaries of a sentence is important for its linguistic analysis, especially for determining its syntactic structure, which is important for determining the prosody, the "melody" of the synthesized voice. However, this paradigm introduces an important latency (proportional to the length of the sentence) which can be at the origin of a certain frustration for the communication partner then constrained to wait for the end of each sentence. Incremental TTS aims at improving the interactivity of an oral communication carried out by means of a TTS, by delivering, as the text is entered, a speech synthesis of a quality close to the one obtained with the help of a traditional TTS (working at the sentence level). The speech synthesis "shadows" the text input (see figure below, taken from Maël Pouget's thesis). One of our approach consists in exploiting neural language models (GPT-like) to predict the future of the textual input and to integrate this prediction into the speech synthesis system (Brooke Stephenson's PhD).

![]() Stephenson
B., Hueber T., Girin. L., Besacier., "Alternate Endings: Improving
Prosody for Incremental Neural TTS with Predicted Future Text
Input", Proc. of Interspeech, 2021, accepted for publication, to
appear (preprint)
Stephenson
B., Hueber T., Girin. L., Besacier., "Alternate Endings: Improving
Prosody for Incremental Neural TTS with Predicted Future Text
Input", Proc. of Interspeech, 2021, accepted for publication, to
appear (preprint)
![]() Stephenson
B., Besacier L., Girin L., Hueber T., "What
the Future Brings: Investigating the Impact of Lookahead for
Incremental Neural TTS", in Proc. of Interspeech, Shanghai,
2020, to appear (preprint)
Stephenson
B., Besacier L., Girin L., Hueber T., "What
the Future Brings: Investigating the Impact of Lookahead for
Incremental Neural TTS", in Proc. of Interspeech, Shanghai,
2020, to appear (preprint)
![]() Pouget,
M., Hueber, T. Bailly, G., Baumann, T., "HMM Training Strategy for
Incremental Speech Synthesis", Proceedings of Interspeech,Dresden,
2015, to appear.
Pouget,
M., Hueber, T. Bailly, G., Baumann, T., "HMM Training Strategy for
Incremental Speech Synthesis", Proceedings of Interspeech,Dresden,
2015, to appear.
![]() Pouget,
M., Nahorna, O., Hueber, T., Bailly, G., "Adaptive
Latency for Part-of-Speech Tagging in Incremental Text-to-Speech
Synthesis", Proceedings of Interspeech, San Francisco, USA,
2016, pp. 2846-2850.
Pouget,
M., Nahorna, O., Hueber, T., Bailly, G., "Adaptive
Latency for Part-of-Speech Tagging in Incremental Text-to-Speech
Synthesis", Proceedings of Interspeech, San Francisco, USA,
2016, pp. 2846-2850.
Visual articulatory feedback
This line of research focuses on the development of tools to assist speech therapy for articulation disorders and on their clinical evaluation. The objective is to allow the patient to visualize his/her own articulatory movements, and in particular those of his/her tongue, of which he/she is generally unaware, in order to better correct them. A first approach uses ultrasound: the patient visualizes his/her tongue movements and compares them in real time to a target movement that he/she tries to imitate. This protocol has been evaluated in the context of post-glossectomy disorders (Revison trial, in collaboration between Lyon University Hospital, DDL, and Rocheplane Medical Center), and of strokes (in collaboration with LPNC laboratory).
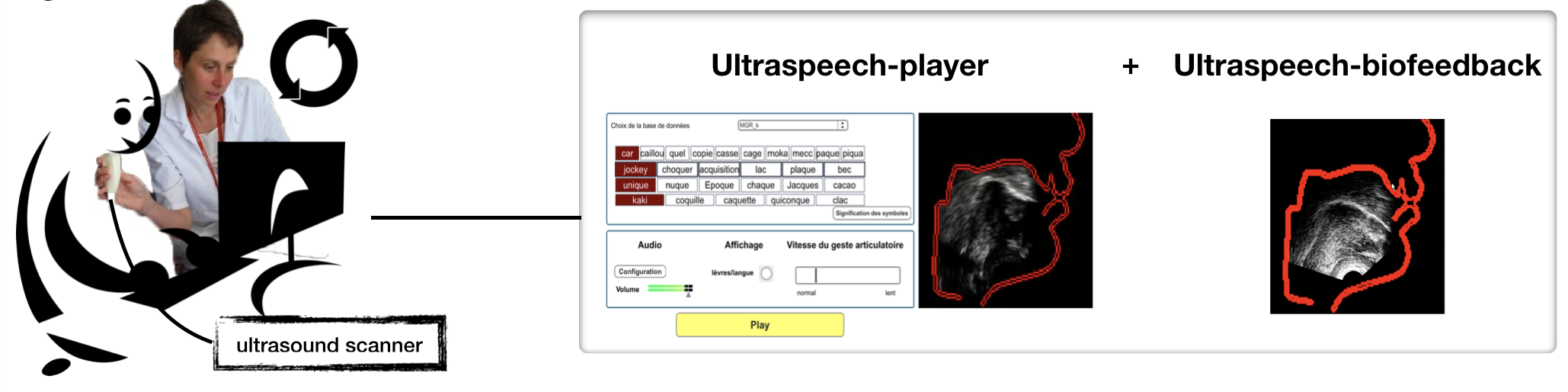
![]() Girod-Roux,
M., Hueber, T., Fabre, D., Gerber, S., Canault, M., Bedoin, N.,
Acher, A., Beziaud, N., Truy, E., Badin, P., Rehabilitation
of speech disorders following glossectomy, based on, ultrasound
visual illustration and feedback, Clinical Linguistics &
Phonetics, doi: 10.1080/02699206.2019.1700310 (preprint).
Girod-Roux,
M., Hueber, T., Fabre, D., Gerber, S., Canault, M., Bedoin, N.,
Acher, A., Beziaud, N., Truy, E., Badin, P., Rehabilitation
of speech disorders following glossectomy, based on, ultrasound
visual illustration and feedback, Clinical Linguistics &
Phonetics, doi: 10.1080/02699206.2019.1700310 (preprint).
![]() Haldin
C., Loevenbruck H., Hueber T., Marcon V., Piscicelli C., Perrier
P., Chrispin A., Pérennou D., Baciu M., (2020) Speech
rehabilitation in post-stroke aphasia using visual illustration
of speech articulators: A case report study, Clinical
Linguistics & Phonetics, DOI: 10.1080/02699206.2020.1780473 (preprint)
Haldin
C., Loevenbruck H., Hueber T., Marcon V., Piscicelli C., Perrier
P., Chrispin A., Pérennou D., Baciu M., (2020) Speech
rehabilitation in post-stroke aphasia using visual illustration
of speech articulators: A case report study, Clinical
Linguistics & Phonetics, DOI: 10.1080/02699206.2020.1780473 (preprint)
The second approach aims at getting rid of a costly ultrasound imaging device and uses signal processing, machine learning and 3D synthesis techniques to automatically animate an articulatory talking head, i.e. a 3D avatar allowing to visualize the inside of the vocal tract, only from the user's voice, and in real time.
Constraining the latent representations of a variational auto-encoder
In the context of a collaboration with the company Arturia (CIFRE thesis of Fanny Roche), we are interested in the control of the timbre of a synthetic sound from high level symbolic descriptors. The targeted synthesizer must for example allow to make a sound more "aggressive", "warmer", etc.. We have proposed a technique based on VAE variational autoencoders, whose latent dimensions we have constrained to approach a set "psychoacoustic" dimensions, extracted from human evaluation of musical sounds.
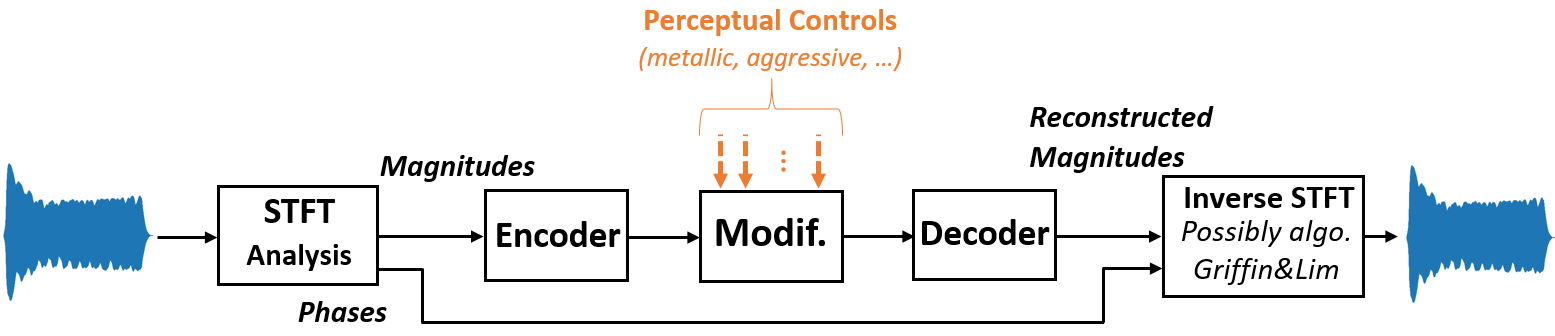
![]() Roche,
F., Hueber, T., Garnier, M., Limier, S., & Girin, L. (2021).
Make That Sound
More Metallic: Towards a Perceptually Relevant Control of the
Timbre of Synthesizer Sounds Using a Variational Autoencoder.
Transactions of the International Society for Music Information
Retrieval, 4(1), pp. 5266.
Roche,
F., Hueber, T., Garnier, M., Limier, S., & Girin, L. (2021).
Make That Sound
More Metallic: Towards a Perceptually Relevant Control of the
Timbre of Synthesizer Sounds Using a Variational Autoencoder.
Transactions of the International Society for Music Information
Retrieval, 4(1), pp. 5266.
![]() Roche,
F.,. Hueber, T., Limier, S, Girin. L., Autoencoders
for music sound modeling : a comparison of linear, shallow,
deep, recurrent and variational models. In Proc. of SMC.
Malaga, Spain, 2019.
Roche,
F.,. Hueber, T., Limier, S, Girin. L., Autoencoders
for music sound modeling : a comparison of linear, shallow,
deep, recurrent and variational models. In Proc. of SMC.
Malaga, Spain, 2019.
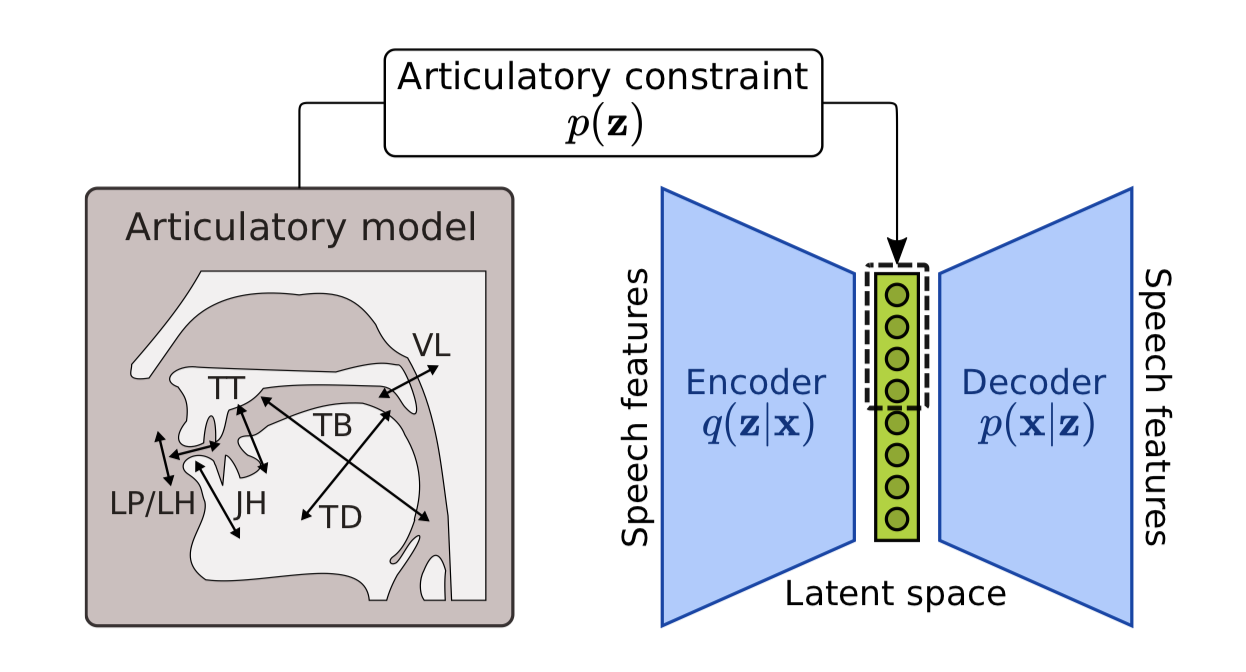 We
then applied this regularization technique to speech. We were
interested in simulating a motor simulation process during the
processing of an auditory stimulus by the brain. Here, the VAE
encoder is used to "project" an auditory stimulus to a latent
space whose dimensions are constrained to encode articulatory
information. We were able to show that this articulatory
constraint improves learning speed and model accuracy, and gives
better performance in a speech denoising task than an
unconstrained VAE.
We
then applied this regularization technique to speech. We were
interested in simulating a motor simulation process during the
processing of an auditory stimulus by the brain. Here, the VAE
encoder is used to "project" an auditory stimulus to a latent
space whose dimensions are constrained to encode articulatory
information. We were able to show that this articulatory
constraint improves learning speed and model accuracy, and gives
better performance in a speech denoising task than an
unconstrained VAE.
![]() Georges
M-A, Girin L., Schwartz J-L, Hueber, T., "Learning robust speech
representation with an articulatory-regularized variational
autoencoder", Proc. of Interspeech, 2021, pp, 3335-3349 (preprint)
Georges
M-A, Girin L., Schwartz J-L, Hueber, T., "Learning robust speech
representation with an articulatory-regularized variational
autoencoder", Proc. of Interspeech, 2021, pp, 3335-3349 (preprint)
Self-supervised learning of acoustic-articulatory relationships
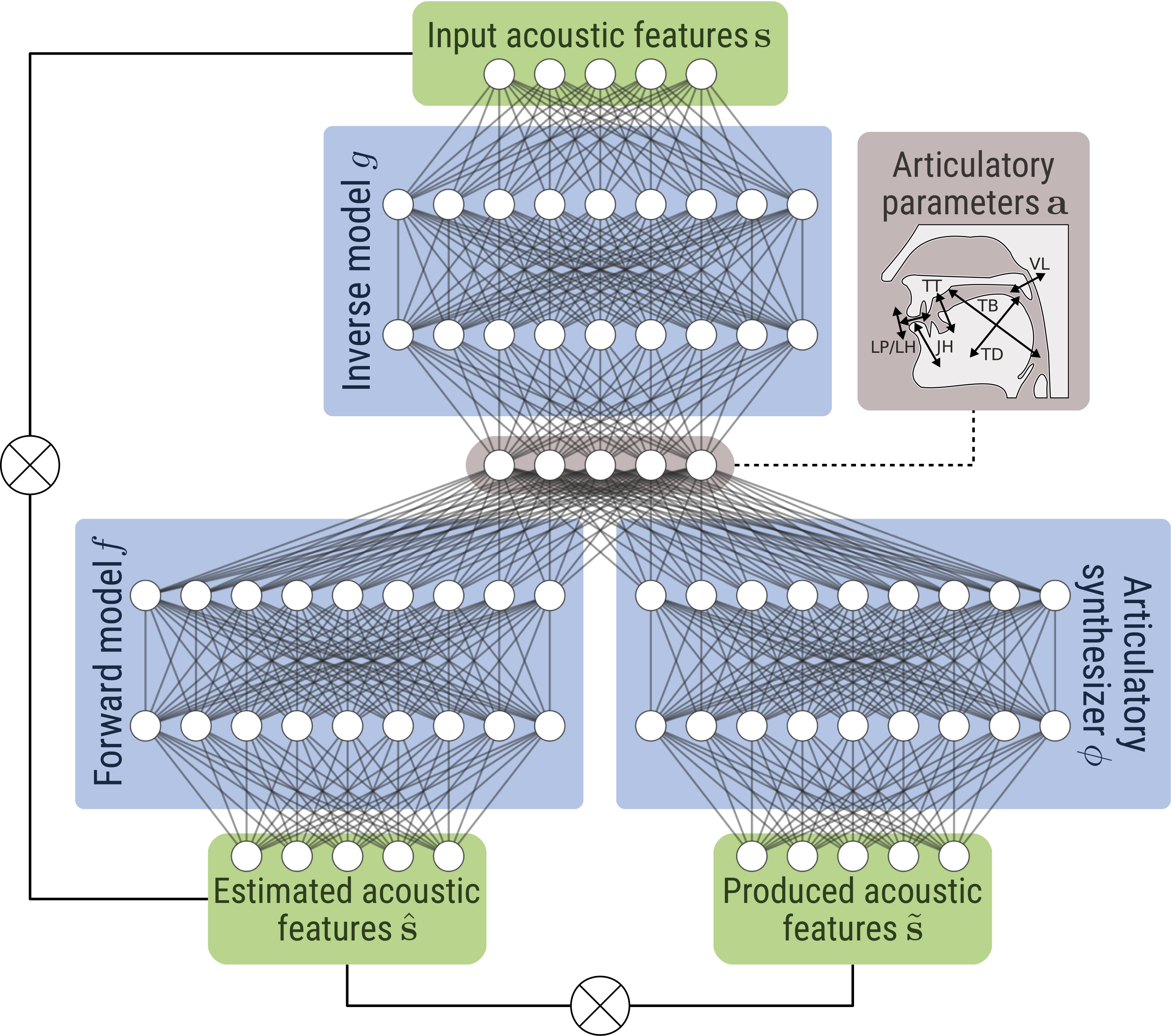
Most of the artificial speech perception and production systems (i.e. ASR, articulatory synthesizer, TTS) exploit statistical models whose parameters are generally estimated by using supervised machine learning. This supervised learning of the links between the different spaces of speech representation (acoustic, articulatory, linguistic) seems to be far from the way a human perceives, processes and produces speech. In particular, we are interested in how a child learns the relationship between the sound of speech and the associated articulatory gesture. We are developing a communicating agent, based on deep learning techniques, capable of learning these sensory-motor relationships in a self-supervised manner, by attempting to repeat the auditory stimuli it perceives (Marc-Antoine George's PhD).
![]() Georges
M-A, Diard, J., Girin, L., Schwartz J-L, Hueber, T., "Repeat
after me: self-supervised learning of acoustic-to-articulatory
mapping by vocal imitation", Proc. of ICASSP, to appear
Georges
M-A, Diard, J., Girin, L., Schwartz J-L, Hueber, T., "Repeat
after me: self-supervised learning of acoustic-to-articulatory
mapping by vocal imitation", Proc. of ICASSP, to appear
Predictive coding of auditory and audiovisual speech
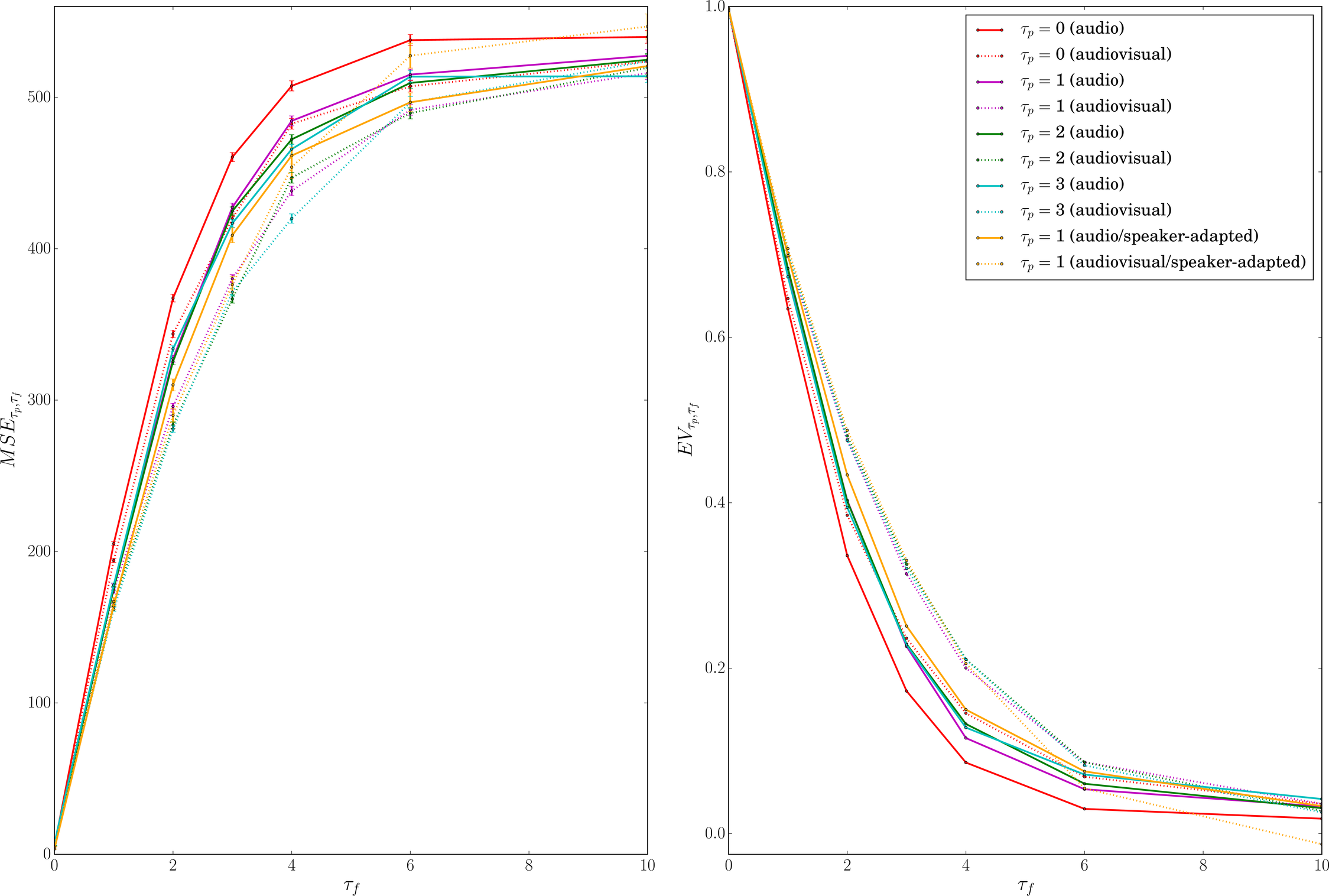 One
of the common pre-text tasks for self-supervised representation
learning is the prediction of the future of an input signal,
based on its past. This paradigm, called predictive coding, is
also very present in cognitive science and neuroscience. It
assumes that our brain implements an online inference algorithm
of future sensory inputs, from past sensory inputs. For speech,
this prediction would be based on the search for regularities in
the acoustic signal, but would also recruit the motor and
linguistic levels. Using convolutional networks trained on large
multi-speaker databases, we quantified the usefulness of such a
strategy, for different time spans (from 25 to 150ms), for
auditory and audiovisual speech.
One
of the common pre-text tasks for self-supervised representation
learning is the prediction of the future of an input signal,
based on its past. This paradigm, called predictive coding, is
also very present in cognitive science and neuroscience. It
assumes that our brain implements an online inference algorithm
of future sensory inputs, from past sensory inputs. For speech,
this prediction would be based on the search for regularities in
the acoustic signal, but would also recruit the motor and
linguistic levels. Using convolutional networks trained on large
multi-speaker databases, we quantified the usefulness of such a
strategy, for different time spans (from 25 to 150ms), for
auditory and audiovisual speech.
![]() Hueber,
T., Tatulli, E., Girin, L., Schwartz, J-L., "Evaluating
the potential gain of auditory and audiovisual speech
predictive coding using deep learning", Neural
Computation, vol. 32 (3), to appear (preprint,
source code,
dataset/pretrained
models)
Hueber,
T., Tatulli, E., Girin, L., Schwartz, J-L., "Evaluating
the potential gain of auditory and audiovisual speech
predictive coding using deep learning", Neural
Computation, vol. 32 (3), to appear (preprint,
source code,
dataset/pretrained
models)
Grenoble Images Parole Signal Automatique laboratoire
UMR 5216 CNRS - Grenoble INP - Université Joseph Fourier - Université Stendhal