
Image

Retour articulatoire visuel temps réel par échographie linguale augmentée
Communiqué
Le principe du "visual biofeedback" consiste à rendre accessible à une personne une information sur le fonctionnement d'un de ses organes dont il n'a naturellement peu conscience. Dans le contexte de cette étude, il s'agit de montrer à un locuteur les mouvements de sa langue lorsqu'il parle et de l'aider ainsi à améliorer sa prononciation.
Dans le système proposé, les mouvements de la langue sont capturés à la l’aide d’une sonde échographique placées sous la mâchoire. Un algorithme d’apprentissage automatique (machine learning) intitulé "Cascaded Gaussian Mixture Regression (C-GMR)", sur lequel les chercheurs travaillent depuis plusieurs années, est ensuite utilisé pour animer automatiquement, à partir des images échographiques, une tête parlante articulatoire. Il s’agit d’un avatar virtuel qui révèle par transparence le mouvement des articulateurs cachés comme la langue. La tête parlante articulatoire permet de rendre la visualisation de la langue plus intuitive pour le patient que l’image échographique brute, car elle montre également les dents, le palais, le pharynx, etc. (on parle alors d’échographie augmentée).
Dans cette étude, les chercheurs ont de plus montré la capacité de l’algorithme C-GMR à extrapoler à des mouvements articulatoires non maitrisés par l’utilisateur lorsqu’il commence à utiliser le système. Propriété indispensable pour les applications visées. La perspective est maintenant de tester ce système avec de « vrais » apprenants de langue seconde et des personnes présentant un trouble de l’articulation nécessitant une prise en charge orthophonique.
Ce travail, publié dans la revue internationale Speech Communication, fait l’objet d’une collaboration avec Inria (Grenoble) et s’inscrit dans le cadre de la thèse de Diandra Fabre soutenue en décembre 2016.
>> Lien vers l’article Speech Communication
Automatic animation of an articulatory tongue model from ultrasound images of the vocal tract
Diandra Fabre (1), Thomas Hueber (1), Laurent Girin (1;2), Xavier Alameda-Pineda (2;3), Pierre Badin (1)
Speech Communication, Volume 93, October 2017, Pages 63-75
https://doi.org/10.1016/j.specom.2017.08.002
(1) GIPSA-lab, Grenoble, France
(2) INRIA, Perception Team, Montbonnot, France
(3) Univ. of Trento, DISI, Trento, Italy
>> Lien vers l’article présentant l’algorithme C-GMR
Hueber, T., Girin, L., Alameda-Pineda, X., Bailly, G. (2015), "Speaker-Adaptive Acoustic-Articulatory Inversion using Cascaded Gaussian Mixture Regression", in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 12, pp. 2246-2259 (https://doi.org/10.1109/TASLP.2015.2464702)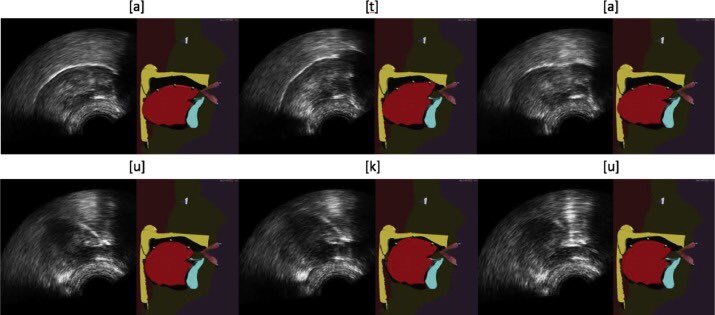
Pour 2 séquences (ata, et oukou, à gauche l’image échographique d’un locuteur tiers, à droite la tête parlante animée automatique à l’aide de la technique C-GMR)
English summary
Visual biofeedback is the process of gaining awareness of physiological functions through the display of visual information. As speech is concerned, visual biofeedback usually consists in showing a speaker his/her own articulatory movements, which has proven useful in applications such as speech therapy or second language learning. This article presents a novel method for automatically animating an articulatory tongue model from ultrasound images. Integrating this model into a virtual talking head enables to overcome the limitations of displaying raw ultrasound images, and provides a more complete and user-friendly feedback by showing not only the tongue, but also the palate, teeth, pharynx, etc. Altogether, these cues are expected to lead to an easier understanding of the tongue movements. Our approach is based on a probabilistic model which converts raw ultrasound images of the vocal tract into control parameters of the articulatory tongue model. We investigated several mapping techniques such as the Gaussian Mixture Regression (GMR), and in particular the Cascaded Gaussian Mixture Regression (C-GMR) techniques, recently proposed in the context of acoustic-articulatory inversion. Both techniques are evaluated on a multispeaker database. The C-GMR consists in the adaptation of a GMR reference model, trained with a large dataset of multimodal articulatory data from a reference speaker, to a new source speaker using a small set of adaptation data recorded during a preliminary enrollment session (system calibration). By using prior information from the reference model, the C-GMR approach is able (i) to maintain good mapping performance while minimizing the amount of adaptation data (and thus limiting the duration of the enrollment session), and (ii) to generalize to articulatory configurations not seen during enrollment better than the GMR approach. As a result, the C-GMR appears to be a good mapping technique for a practical system of visual biofeedback.
Keywords
Speech production, Ultrasound imaging, Articulatory talking head, Adaptation, Gaussian mixture regression, Biofeedback